


Alle reden über das neue Buch, in dem es vielleicht um die Männer bei der Bildzeitung geht oder vielleicht auch nicht – wie bringe ich ein GPT-Sprachmodell dazu, den Text für mich zu lesen?
Stuckrad-Barre ist nicht so meins – aber selbst für hart gesottene Fans war die Veröffentlichung von „Noch wach?“ eine Prüfung: Das Buch war in den Schlagzeilen, aber es gab so gut wie nichts vorab; wollte man über das frisch veröffentlichte Buch mitreden – vielleicht sogar in einer Radio-Frühsendung? – war konzentrierte Nachtarbeit angesagt.
Könnte man sich von einer Text-KI wie ChatGPT beim Lesen helfen lassen? Sich die wichtigen Stellen, äh, wiederfinden lassen? Mit dem normalen ChatGPT-Chatbot funktioniert das Lies-es-für-mich-Kunststück nur bei vergleichsweise kurzen Texten. Ich zeige, wie es im Prinzip auch mit Stuckrad-Barre geht – welche Grenzen die KI uns setzt, und wie KIs mit längeren Texten umgehen.
Weiterlesen: Kann ich KI für mich den Stuckrad-Barre lesen lassen?Die KI setzt harte Grenzen
Klar: Wer sich einen mittelkurzen Text zusammenfassen lassen will – sagen wir, diesen WDR-Hintergrundartikel zum Krieg im Sudan – kopiert einfach den Text in das ChatGPT-Fenster und schreibt: „Fasse mir diesen Text knapp zusammen.“ Und man kann dann Fragen zum Text stellen – etwa, um welche Art von Konflikt es sich handelt.

Dass wir diese Interpretationen nicht ungeprüft übernehmen sollten, ist ein anderes Thema – aber halten wir fest: Sprachmodelle wie (Chat-)GPT3.5 sind sehr gut darin, Texte zu erfassen, und dazu passende ergänzende Texte zu produzieren. Sie zu verstehen, gewissermaßen – auch wenn die KI nicht über den Sinn des Text nachdenkt, sondern ein Sprachspiel spielt. Enorm nützlich ist das auf jeden Fall – aber es gibt Grenzen. Harte Grenzen.
Sprachmodelle haben ein eingeschränktes Blickfeld – sie können nur eine begrenzte Anzahl von Worten gleichzeitig verarbeiten. Das Modell hat kein Gedächtnis: Wenn ich mit der KI chatte, tut sie das, indem sie einfach jedes mal alle bisherigen Fragen und Antworten noch einmal betrachtet – aber irgendwann ist Schluss:
- GPT3.5-Turbo, die KI hinter dem Standard-ChatGPT-Bot, kann maximal 4.096 Token verarbeiten. Token sind die Zahlen, in die der Computer unsere Worte übersetzt. 3 Worte entsprechen 4-5 Token – 4.096 Token sind etwa 3-4 Seiten Text.
- GPT-4, die Nachfolgegeneration, schafft das Doppelte – 8.192 Token. Allerdings haben sie bisher nur Streber wie ich, die für ChatGPT bezahlen, und auch da nicht alle.
- GPT-4-32k ist eine Spezialversion, die nochmal das Vierfache davon schafft – über 32.000 Token, einige dutzend Seiten Text. Leider können sie nur ausgewählte, programmierkundige Nutzer verwenden – zu beachtlichen Kosten.
Idee: Die Grenzen sprengen!
Noch mal kurz das Problem festgehalten: Sprachmodelle wie GPT-3.5 können sehr gut aufarbeiten, was in ihren Token-Horizont passt. Darüber hinaus haben sie kein Gedächtnis; wozu man sie befragen will, das muss man ihnen mitliefern. Mehr, als die Token-Grenze an Worten zulässt, kann die KI nicht verarbeiten. Und auch, wenn erste Vorab-Studien von Verfahren raunen, mit denen sich der Horizont eines Sprachmodells auf Millionen von Token aufbohren ließe – derzeit ist das, was GPT-4 bietet, die harte Grenze des Machbaren.
Wie wäre es also mit einem Trick? Statt mit dem Volltext arbeiten wir mit Zusammenfassungen – und zwar so:
- Erstelle von jeder PDF-Seite eine Zusammenfassung
- schreibe die Seitennummer davor, damit die KI sich zurechtfindet,
- und übergib diese Zusammenfassung komplett mit unseren Fragen dazu an chatGPT.
- Wir geben der KI außerdem vor, dass sie zusätzliche Informationen anfordern soll, wenn sie sie braucht.
Was kann man damit anfangen? Als etwas unverfänglichere, urheberrechtsneutrale Alternative zu Stuckrad-Barre habe ich mir ein 35-seitiges PDF des Reuters Institute über High-Tech-Alternativen zum Reporter-Notizblock ausgesucht – nicht ganz so hohe Literatur, aber auch fordernd. Das kann man damit – wie wir sehen werden – gut zusammenfassen.
Mit dem kostenlosen chatGPT-Zugang kommen wir aber nur so und so weit. Und das Hin- und Herkopieren nervt. Deshalb:
Zeit für eine Nerdbastelei! (Zum Nachmachen)
Jetzt lasse ich meinen Computer die Arbeit machen. Bestimmte Fähigkeiten der ChatGPT-KI kann man nur ohnehin nur dann nutzen, wenn man sie über eine Computerschnittstelle anspricht – die so genannte API. Ein kleines Programm hilft mir, den Text aus einem PDF zu ziehen, die Zusammenfassungen zu erstellen, und den Dialog mit der KI zu ermöglichen.
Keine Angst: Programmieren muss hier auch heute niemand können, und Programmiersprachen installieren auch nicht. Ich habe meinen Programm-Code hier in ein so genanntes „Notebook“ gepackt – eine Mischung aus Erklärtext und Python-Code. Wer ein Google-Konto hat, kann das Programm durch einen Klick auf den „Open in Colab“-Button laden und es selbst ausprobieren – ein OpenAI-API-Token muss man sich auch noch besorgen, wie gesagt.
Also los: Das Colab starten, durch den ersten „Play“-Button alle Vorbereitungen erledigen, dann den API-Key eintragen – die Einstellungen lassen wir zunächst unverändert. Dann die nächste Codebox starten und das Reuters-PDF hochladen – es ist mit knapp 14.000 Token zu groß selbst für GPT-4. Also löse ich die „Kompression“ aus – was ein paar Minuten dauert und mich rund 3 US-amerikanische Cent für GPT-3.5-API-Nutzung kostet.
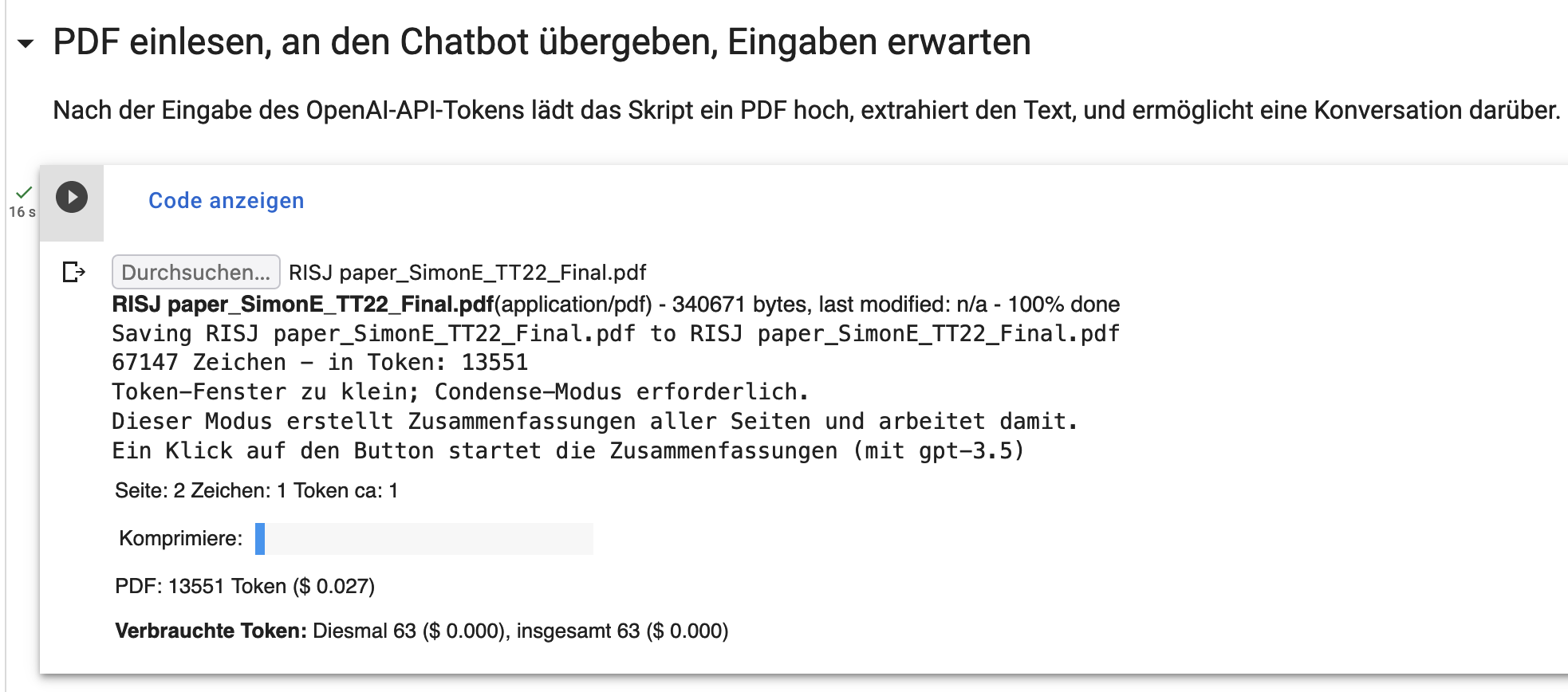
Teurer sind die Fragen an das PDF: Komprimiert bleiben etwa 4.000 Token übrig – so gut ist die Kompressionsrate diesmal nicht. Das lässt unter GPT-3.5 nicht viel Luft für Fragen und Antworten – deshalb schalte ich auf GPT-4 um, zu den zehnfachen Kosten je Frage: Da, wie gesagt, jedesmal der gesamte Zusammenfassungs-Text übergeben werden muss, fallen jedes Mal, für jede Frage, etwa 12 Cent an Kosten an.

Immerhin beantwortet mir GPT-4 brav meine Fragen zum Text – der Zusammenfassungs-Trick scheint zu funktionieren. Aber so richtig alltagstauglich ist das alles nicht. Was tun?
Wie es die Profis machen
Klar: Das hier ist ein Experiment, kein produktionsreifes Tool. Die gibt es natürlich längst: Wenn man ohnehin ein API-Token hat, funktioniert pdfgpt.io sehr gut und ist für Dokumente bis 1000 Seiten ohne Anmeldung nutzbar. Die Analyse des PDF dauert auch nicht so lange wie bei mir, sondern ist in Sekunden erledigt – wie machen die das?
Tools wie pdfgpt.io – es gibt auch schon Open-Source-ChatGPT-Plugins, die ganz genau so arbeiten – nutzen eine andere Eigenschaft von Sprachmodellen wie GPT: Die Fähigkeit, Fingerabdrücke des semantischen Sinns eines Textes zu erstellen – so genannte Embeddings. Das sind lange Zahlenketten, und wenn man mehrere dieser Zahlenketten hat, kann man sie in eine Datenbank schreiben. Wenn die Embeddings von zwei Absätzen sich ähneln, geht es darum um verwandte Themen – das ermöglicht eine „semantische Suche“, eine Suche nicht nach Stichworten, sondern nach Sinn-Ähnlichkeiten.
Die semantische Suche in einem PDF-Dokument – zum Beispiel in unserem Reuters-PDF – funktioniert also so:
- Erstelle von jedem Absatz einen „Embedding“-Fingerabdruck.
- Schreibe sie alle in eine Datenbank.
- Wenn eine Frage gestellt wird, errechne für sie auch ein Embedding – und vergleiche es mit den Embeddings in der Datenbank.
- Ziehe für die Absätze mit den ähnlichsten Embeddings den Volltext – und ein paar Absätze davor und danach, um den Kontext zu haben. Übergib das zusammen mit der Frage an GPT.
- Lass das Sprachmodell die Frage beantworten.
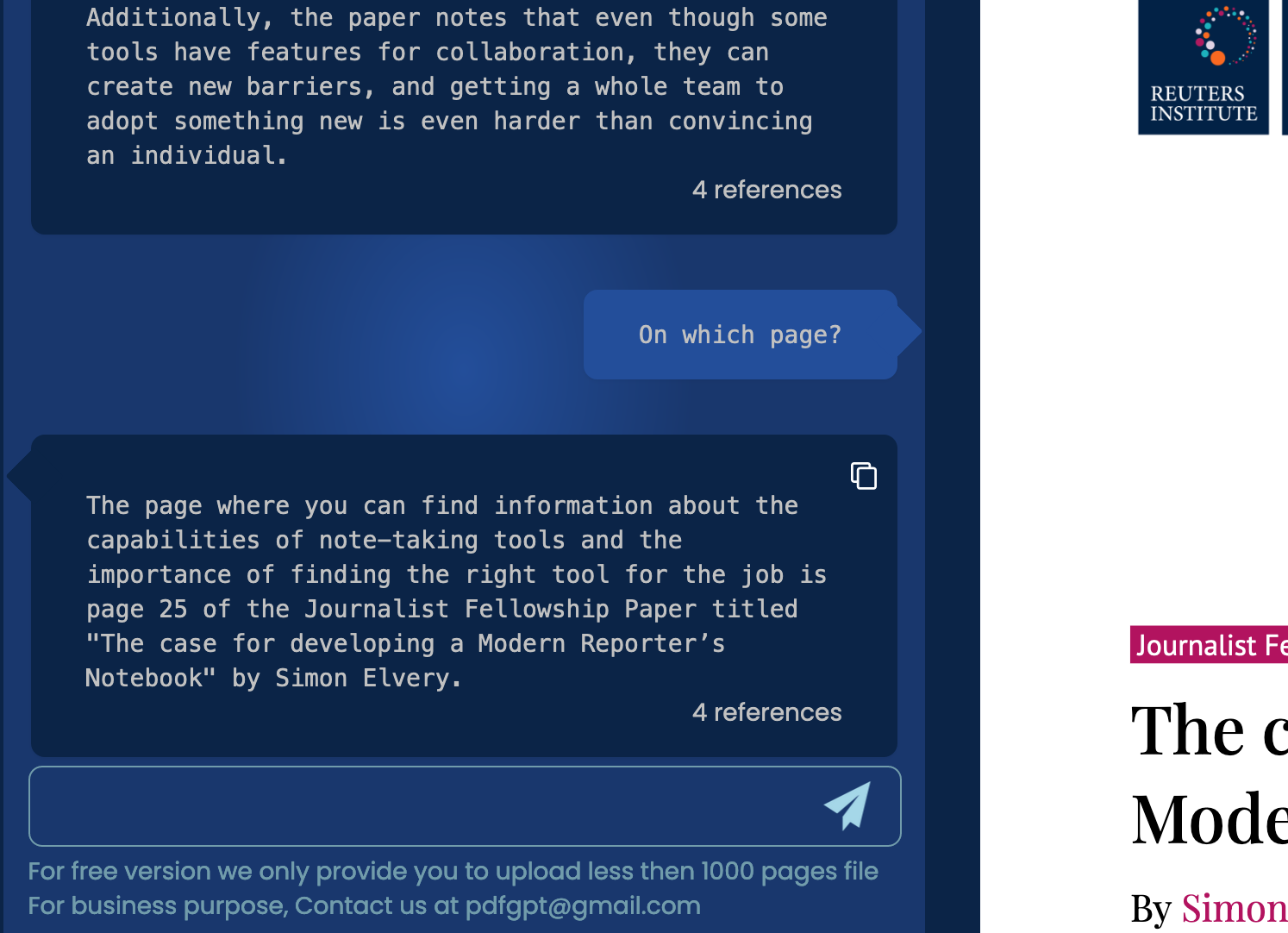
Das funktioniert mit dem Reuters-Papier prima, also würde es sicher auch mit einem PDF des Stuckrad-Barre-Buchs funktionieren (wendet euch vertrauensvoll an die Pressestelle von Kiepenheuer & Witsch). Oder mit den internen Dokumentationen öffentlich-rechtlicher Rundfunksender. Die allerdings zu großen Teilen nur als abfotografierte Ausdrucke vorliegen, aber das ist noch mal ein ganz, ganz anderes Thema.
Auch lesenswert:
- Besser prompten: Gib der KI gut strukturierte ROMANE!
- Wie funktionieren die Custom GPTs – die neuen KI-Assistenten?
- Die Psychologie der KI – die 8 größten Irrtümer
Schreibe einen Kommentar