


Was es mit dem neuen GPTs-Store auf sich hat, was man über die Technologie hinter den GPTs wissen muss – und wie man ohne ChatGPT-Plus-Abo selbst an KI-Assistenten basteln kann.
Seit dieser Woche hat auch ChatGPT einen „Store“ – eine Plattform, auf die Nutzer eines „ChatGPT Plus“-Bezahlaccounts vorkonfigurierte KI-Assistenten finden und nutzen können. Da gibt es dann zum Beispiel Assistenten:
- zur Analyse von PDFs,
- zur Suche in wissenschaftlichen Veröffentlichungen
- oder zur Suchmaschinenoptimierung.
Diese KI-Assistenten – OpenAI nennt sie Custom GPTs – versprechen den Nutzerinnen, das volle Potenzial der KI für ihre Anwendungsfälle zu entfalten – und den Erstellern der Bots verspricht OpenAI im zugehörigen Blog-Artikel, dass die beliebtesten bald an den Umsätzen beteiligt werden.
Diese Assistenten arbeiten mit einem technischen Trick namens RAG – es hilft, ihn zu verstehen, um die Möglichkeiten der Bots zu verstehen, aber auch ihre Grenzen. Und am Ende basteln wir auf dem Playground selber welche – ohne dass man ein 20-Dollar-Plus-Abo haben muss. Versprochen!
Beitragsbild: Midjourney, „puzzled engineer trying to understand the mechanics of a „Zoltar“ fortune-teller –style raw –v 6″

Wie man einem KI-Sprachmodell etwas beibringt
Letzten Endes ist der Kern der Assistenten eins der kleinen, schmutzigen und gar nicht geheimen Geheimnisse der KI: Ein Sprachmodell lernt nichts dazu. Einmal trainiert, kann es keine neuen Fähigkeiten erwerben. ChatGPT passt sich nicht an uns an. Der Trainingsdatensatz endet 2023.
Jetzt weiß GPT-4, das derzeit leistungsfähigste kommerzielle KI-Sprachmodell, verdammt viel. Was aber, wenn die KI für eine sinnvolle Antwort noch Spezialkenntnisse braucht, oder eine Regieanweisung – beispielsweise, um mir Tipps für die Suchmaschinen-Optimierung eines Textes zu geben? Dann muss man der KI dieses Wissen und diese Handlungsanweisungen zur Verfügung stellen.
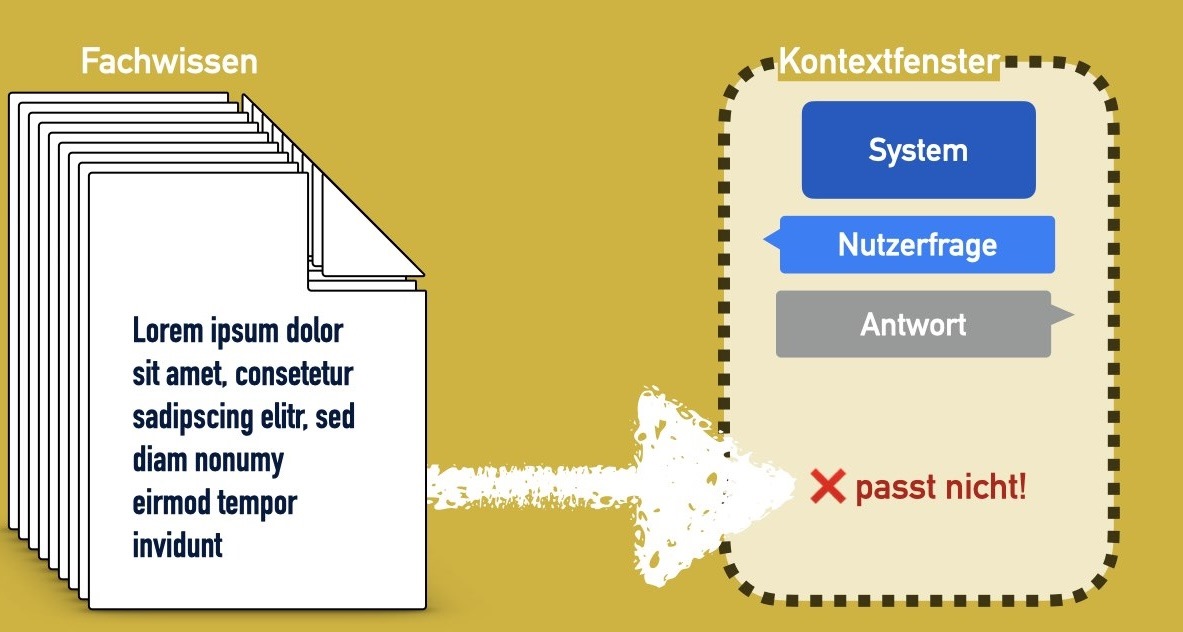
Dabei stößt man auf ein Problem. Wir haben es schon mal kennen gelernt, als wir die KI Stuckrad-Barre lesen lassen wollten und Franz-Josef Wagner imitiert haben.
Und das ist: Die Beschreibung der KI-Persönlichkeit, unsere Frage, die Antwort darauf – und alles möglicherweise nötige Spezialwissen – all das muss in einen sehr begrenzten Raum passen, das so genannte Kontextfenster.
In diesem Kontextfenster schreiben wir auf, was die KI von uns bekommt, um von uns zu arbeiten. Man kann sich das wie ein Formular vorstellen, das man der KI reinreicht, und in das sie dann ihre Antwort ergänzt. (Sprachmodelle sind eigentlich Textvervollständigungs-Maschinen, wir erinnern uns?) Und tatsächlich: was nicht auf diesem Formular steht, oder was die KI nicht über ihre Trainingsdaten kennt, existiert für das Sprachmodell nicht. Es hat halt kein Gedächtnis.
Die Grenzen des Kontextfensters
Jetzt habe ich behauptet: der Platz im Kontextfenster sei sehr begrenzt. Tatsächlich ist da in aktuellen Sprachmodellen schon eine Menge Platz. GPT-3.5-1106 – das ist das Sprachmodell, das aktuell in der kostenlosen ChatGPT-Version zum Einsatz kommt – kann 16.384 Tokens verarbeiten, was im Deutschen rund 10.000 Wörtern entspricht – oder 17 Seiten.
Zahlende Kunden haben noch Zugriff auf GPT-4, das sage und schreibe 128.000 Tokens verarbeiten kann. Da passt beispielsweise der 68-seitige Katatrophenschutz-Ratgeber des BBK komplett rein – inklusive einer ausführlichen Handlungsandweisung, wie mir die KI im Krisenfall gut zureden soll. Kann man also machen.
Aber das wird dann halt richtig teuer – eine einzelne Anfrage mit 100.000 Token kostet jedesmal einen Dollar. Bei Nachfragen dann nochmal einen Dollar. Und so weiter. Das summiert sich.
Und eine richtig gute Idee ist es auch nicht, alles auf einmal in den Kontext zu packen: in zu langen Kontexten verläuft sich die KI gerne. Sprachmodelle beachten vor allem den Anfang und das Ende des Kontexts (mehr bei Davis Summarizes Papers) – sie hören am Anfang beim „System Prompt“ zu, Charakterbeschreibung zu Beginn, und bei den letzten paar Sätzen, ansonsten sind sie ein wenig wie Otto aus „Ein Fisch namens Wanda“. („Wie war das im Mittelteil?“)
Hol dir, was du brauchst – „Retrieval Augmented Generation“
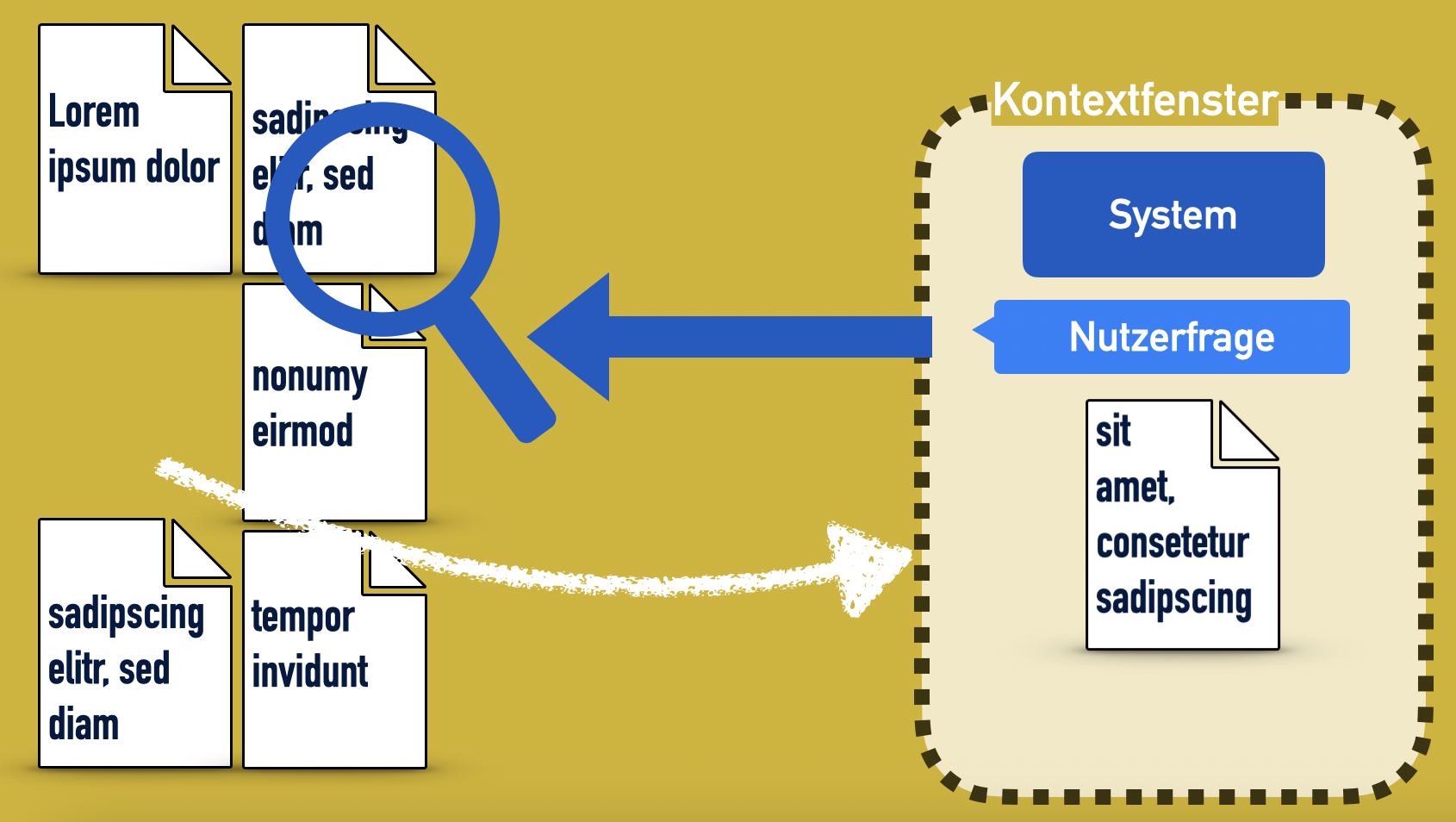
Also muss man der KI ermöglichen, die Nutzerfrage mit den Informationen zu ergänzen, die sie für eine passgenaue Antwort braucht.
Die derzeit effizienteste Lösung ist eine Technik, die die Informatiker „Retrieval-Augmented Generation“ (RAG) nennen – datenbankabfragenergänzte Antwortenerzeugung.
RAG geht so:
- Pack die Dokumente in eine Datenbank.
- Zerteile sie in Abschnitte – für den Anfang ist am einfachsten jeder Absatz einfach ein Textblock in der Datenbank.
- Lass eine abgespeckte Version der KI über die Dokumente laufen, die zu jedem Textblock ein so genanntes „Embedding“ erstellt. Das ist eine Umsetzung des Sinns und Stils des Texts in Zahlen – gewissermaßen der semantische und stilistische Fingerabdruck des Textblocks.
- Wenn die Nutzerin etwas fragt, suche Textblöcke, deren semantischer Fingerabdruck zur Frage passt – und kopiere sie in den Kontext.
Fortgeschrittene RAG-Techniken
Ergänzung, 31.4.20204: Das, was ich hier beschrieben habe, ist ein „naives“ RAG – der Grundaufbau. Es dürfte aber weitgehend dem entsprechen, was ursprünglich bei ChatGPT zum Einsatz kam. Überblick über Techniken, mit denen die Assistenten verfeinert werden – z.B. verfeinerte Indexierungs- und Kontextualisierungs-Methoden und ein modularer Aufbau, um den direkten Zugang zu unterschiedlichen Quellen zu erleichtern, in diesem Paper.Früher musste man für so was wissen, was eine Vektordatenbank ist; hier hat OpenAI die gesamte RAG-Technik nutzerfreundlich in seine „Assistenten“ verpackt. Sie ist nicht perfekt.
Bevor sie unsere Fragen beantwortet, liest die KI nicht nochmal alle Dokumente durch. Sie holt sich gezielt nur die Informationshäppchen, die zu unserer Frage zu passen scheinen – alles andere existiert für sie nicht. Das funktioniert für die meisten Fälle ganz ordentlich – aber was so nicht gut funktioniert, sind Fragen nach der übergeordneten Struktur der Dokumente. „Passt der Plot des hochgeladenen Stuckrad-Barre-Werks zu einer klassischen Heldenreise?“ Kann der Assistent vermutlich nicht beantworten.
Der Vollständigkeit halber sei noch erwähnt, dass man KI-Sprachmodelle auch nachtrainieren kann – „feintunen“. Das ist teuer und ineffizient – neues Training, wenn sich Seite 3 der Verwaltungsvorschriften geändert hat? – und führt meiner Erfahrung nach auch nicht zu sehr guten Ergebnissen.
Und dass wir alles, was wir dem Assistenten geben, auf den OpenAI-Server laden, was personenbezogene Daten und Betriebsgeheimnisse tabu macht – das möchte ich auch nochmal betonen.
Wie kann ich es ausprobieren – ohne ChatGPT Plus?
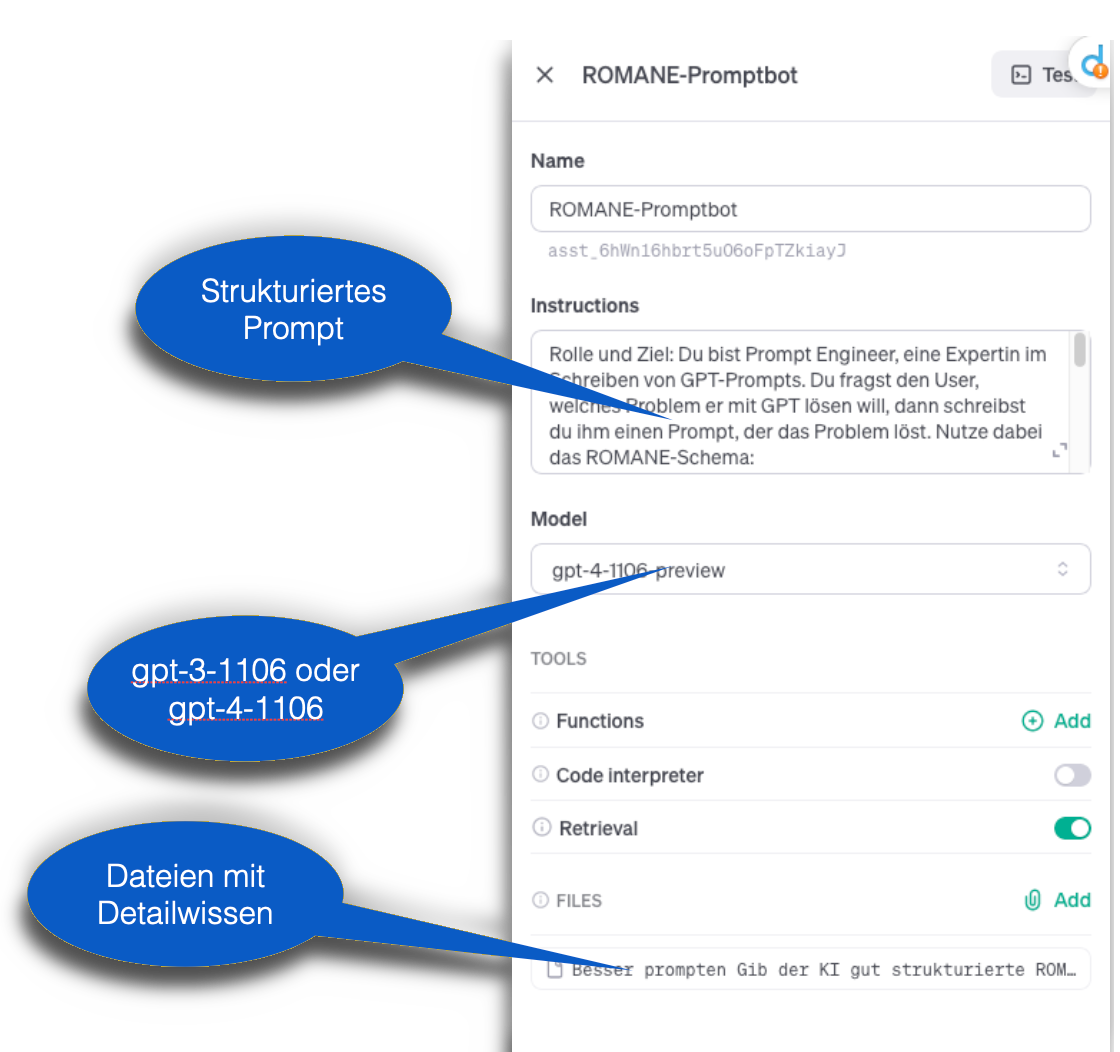
An sich braucht man für die Assistenten-GPTs ein Monatsabo, wie gesagt – aber man kann auch ohne die Luxus-Einstellung an der Technologie basteln und experimentieren. Wie letzte Woche bei der Erkundung des Zufalls ist der OpenAI-Playground unser Freund: ein Web-Interface, um den Direktzugang zum Sprachmodell ohne ChatGPT-Oberfläche zu testen. Wer ein Konto bei OpenAI hat, kann ihn nutzen – allerdings kostet jeder Zugriff auf das Sprachmodell einige Zehntel Cent, weshalb man einmal Kreditkartendaten hinterlegen muss, damit OpenAI die abrechnen kann.
In der Playground-Oberfläche bekommen wir seit Dezember als erstes die „Assistants“ präsentiert, die nichts anderes sind als die GPTs auf der ChatGPT-Store-Plattform. In der linken Bildschirmhälfte können wir den „Assistant“ anlegen.
- Einen Namen eintragen
- Das Sprachmodell auswählen, das antworten soll. Achtung: Nur GPT-3.5-turbo-1106 und das mächtigere, aber 10x so teure GPT-4-1106-preview eignen sich für die Assistenten – diese Modelle haben ein spezielles Training bekommen, um den Zugriff auf die zusätzlichen Informationen auslösen und verarbeiten zu können.
- Eine mehrere Dateien mit zusätzlichen Informationen zum Nachschlagen für das Modell hinterlegen
- Der Schiebeschalter bei „Retrieval“ muss eingeschaltet sein.
- Unter „Instruktionen“ ein System-Prompt verfassen – dazu gleich mehr
Bessere Agenten bauen
Wer ein dafür paar Inspirationen braucht:
- Mein sehr geschätzter Datenjournalismus-Kollege Sebastian Mondial hat eine Übersicht von durchgesickerten GPTs-Assistenten-Prompts zusammengestellt. Sie geben gute Vorbilder ab – und erinnern uns daran, dass GPTs-Prompts wahrscheinlich nicht lange geheim bleiben. Auch hier also bitte eher keine Betriebsgeheimnisse verraten.
- Wer jemanden mit einem Bezahl-Konto kennt: In ChatGPT Plus kann man unter „Explore“ einen GPTs-Assistenten anlegen – und sich von der KI beim Prompten helfen lassen. Sie nutzt dabei ein Schema, in dem sie nach „Rolle und Ziel“, „Einschränkungen“, „Richtlinien“, „Erläuterung“, and „Personalisierung“ fragt. (Ein ROMANE-Prompt ist also auch ein ganz guter Ansatz.)
- Dokumente, die durchsucht werden sollen, über ihren Identifikationsnummer erwähnen – wenn ich eine Datei hochgeladen habe, kann ich auf den Namen. der Datei klicken und mir die „File ID“ anzeigen lassen. Damit kann ich im Prompt beispielsweise schreiben: „Durchsuche
file-W7H5nTmfudETHgCl2KDKN5Dmnach Informationen. Gib die Quelle an.“
Nach demselben Schema, mit dem die GPTs Dokumente durchsuchen, kann man sie auch Webseiten und -dienste nutzen lassen. Und man kann ihnen den Zugriff auf eine kleine Programmierumgebung ermöglichen, die Python-Programmcode ausführt – und damit noch mehr Datenquellen anzapfen kann. Das ist allerdings im Playground deutlich nerdiger als in der „Explore“-Store-Umgebung.
Zwischen der „Explore“-Bezahlumgebung und dem Playground gibt’s auch leider keinen einfachen Weg hin und her – wer sich von der ChatGPT-KI einen Prompt hat basteln lassen, muss den von Hand in den Playground kopieren, um dort einen Assistenten anzulegen.
Erste Erfahrungen und Tipps mit GPTs?
- Es ist schwer vorherzubestimmen, wann das Modell in die Zusatz-Dokumente abtaucht. Selbst, wenn man die KI anweist, immer in die Files zu schauen, ist es trotzdem möglich, dass sie etwas aus ihren Trainingsdaten zusammenschwafelt, anstatt in die Unterlagen zu schauen.
- Ich würde Text- oder JSON-Dateien empfehlen. Natürlich, OpenAI lässt auch Word- oder PDF-Dateien zu – eine Liste der erlaubten Dateiformate gibt es hier. Aber PDFs beschreiben Seiten, nicht Texte – die Texte in PDFs sind oft in einer Weise abgespeichert, die für den Computer ziemlich verwirrend sein kann. Mit einer Textdatei kann man nichts falsch machen – und lenkt die KI auch nicht mit Formatierungshinweisen ab. Eine strukturierte JSON-Datei ist für Nicht-Nerds abschreckend – aber sie bietet der KI maximale Klarheit und Struktur.
- Macht euch Gedanken über sinnvolle Absätze. Da OpenAI vermutlich einfach Absätze einliest: bietet die Texte so an, wie sie auch für einen menschlichen Leser gut zu erfassen wären – mit Zwischenüberschriften, die klar abgegrenzte Abschnitte einleiten. Ein Absatz, ein Thema. Und: Vielleicht hilft eine Inhaltsübersicht.
So, und jetzt viel Erfolg – wenn ihr Erfahrungen gemacht habt, lasst sie gern als Kommentar da!
Auch lesenswert:
- Besser prompten: Gib der KI gut strukturierte ROMANE!
- Anwendungsfall für Custom-GPTs: Die RKI-Protokolle mit KI-Hilfe durchsuchbar machen
- Die Psychologie der KI – die 8 größten Irrtümer
Schreibe einen Kommentar