

Der Versuch, 2.200 Protokollseiten mit KI zu analysieren, hatte ja vor einigen Wochen allenfalls mittelgut geklappt – allerdings mit wichtigen Lehren für einen neuen Anlauf. Wie gut, dass gerade ein neuer Anwendungsfall um die Ecke kommt – und ein neues Tool in einer brandneuen Version.
Meine wunderbare Freundin und Kollegin Heike Borufka ist Gerichtsreporterin – und zudem Host des „Verurteilt!“-Podcasts, in dem sie seit inzwischen fünf Jahren echte Fälle, echte Urteile und echtes Leben verhandelt, zusammen mit dem Multitalent Basti Red. Die Live-Shows der beiden in der Frankfurter „Käs“ sind zu Recht immer schnell ausverkauft.

Neulich waren sie an einem anderen Ort mit einer anderen Veranstaltung: einer Verurteilt-Fan-Quizshow. Über 100 Fälle bieten schließlich genug Material. Wäre das nicht ein großartiger Anwendungsfall für einen KI-Assistenten? War es. Die KI hatte beim Quizabend Premiere und hat auch am vergangenen Mittwoch in der Käs Zuschauer-Fragen rund um die vergangenen Fälle beantwortet. Nicht alle Fragen, mind you, aber insgesamt war es verdammt praktisch, das umfangreiche Material mit Unterstützung durchschauen zu können, ohne genaue Stichworte kennen zu müssen – zumal bei der Transkription der Podcasts der eine oder andere Name verunstaltet wurde (aus Gäfgen macht das Verschriftlichungs-Modell „Geffken“, aus Tugce „Tutsche“).
Wer nicht so oft Shows veranstaltet: andere journalistische Anwendungsfälle für dieses Werkzeug wären zum Beispiel…
- Interview-Unterstützung: Alle Aussagen und Interviews eines Politikers in die KI einspeisen – und sich damit von der KI schnell aufarbeiten lassen, was er/sie bisher zu einem Thema gesagt hat.
- Faktenchecker-Bot: Wenn Nutzerinnen und Nutzer Fragen zu Sachen stellen können, die sie im Netz gehört haben, haben Faktenchecks endlich eine Chance; die brasilianische Investigativ-Seite „Aos Fatos“ hat das erfolgreich so gebaut (Nieman Lab)
- Regeln nachschlagen: Wie war das nochmal mit den Reiseanträgen? Die KI erklärt es mir – nachdem ich sie mit allen Regeln und Dienstanweisungen gefüttert habe.
Bei all diesen Anwendungsfällen ist es enorm wichtig, die Einschätzung des Sprachmodells nachprüfen zu können; exakte Quellen und Belege zu bekommen – schon wegen der fatalen Neigung von Sprachmodellen, Dinge falsch zu verstehen oder sogar zu erfinden (Makaberes Beispiel bei Gary Marcus). Transparenz ist King, eine Disziplin, in der ChatGPT leider patzt, wie wir ja auch beim RKI-Protokolle-Bot gesehen hatten.
Aber es gibt ein fantastisches neues Tool, das besser und transparenter arbeitet – und das jede/r herunterladen und einsetzen kann.
Verba, der Golden RAGtriever
Dieses Open-Source-Tool eines Berliner Startups – hier der Link zum Github – ist ideal für uns Journalistinnen und Journalisten. Man kann es mit etwas Bastel-Geschick auch auf dem eigenen Laptop zum Laufen bringen und überall hin mitnehmen. In der ganz neuen Fassung muss man dann nicht mal mehr eine Internet-Verbindung haben, sondern kann ein Sprachmodell einsetzen, das lokal auf dem eigenen Rechner läuft; ohne irgendetwas an OpenAI zu übertragen – ich sage aber gleich, dass man dafür (beispielsweise) ein neueres Macbook mit 48GB Speicher oder mehr braucht, um ein halbwegs vernünftiges Modell einsetzen zu können.
Einen Werkstatt-Bericht mit Hinweisen, wie man es installiert, findet ihr demnächst hier im Blog.
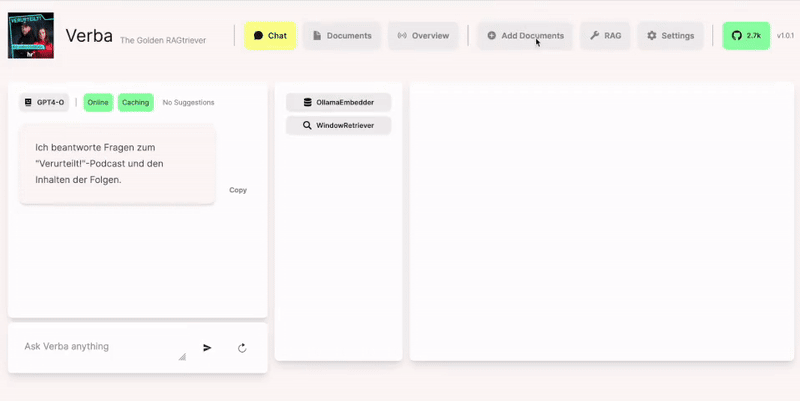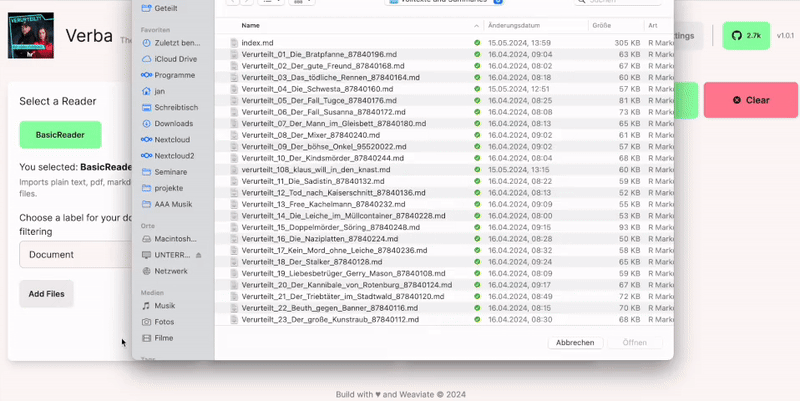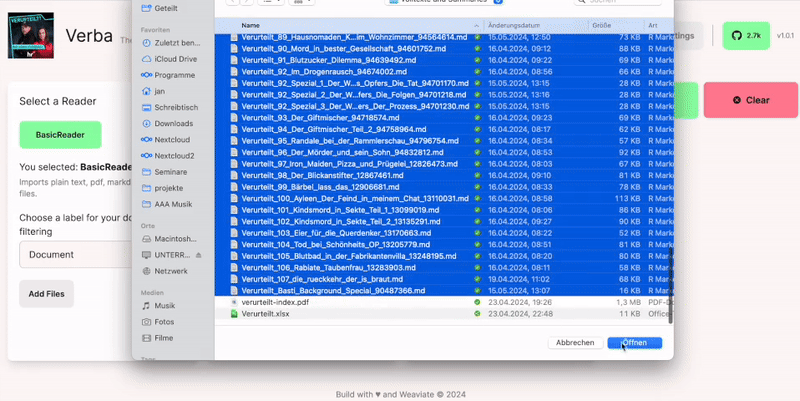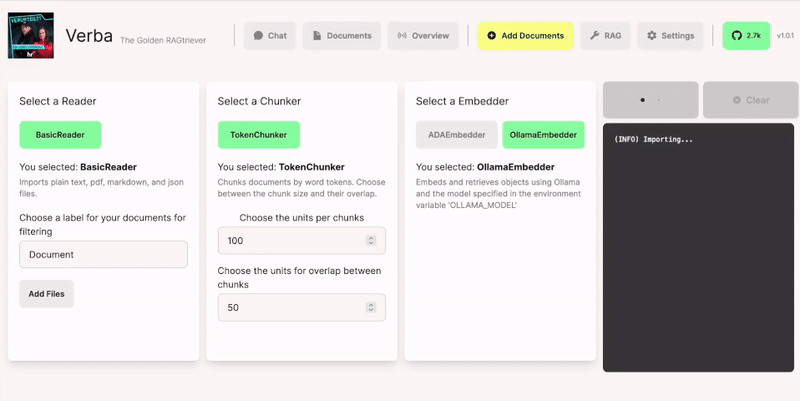
Was Verba tut: Es liest die Text- oder PDF-Dokumente ein, zerlegt sie dann in Schnipsel von 250 Token, das sind etwa 200 Wörter oder ein kurzer Absatz. Jeder dieser Schnipsel enthält noch den letzten Satz des vorigen und den ersten Satz des nächsten. Dann bekommt jeder Schnipsel einen semantischen Fingerabdruck – die KI erstellt ein Embedding, eine Reihe von mehreren tausend Zahlenwerten, in dem der Sinn des Textes codiert ist, und schreibt ihn in eine Datenbank auf auf dem Laptop.
Man kann sich es so vorstellen, dass die KI alle Texte und Bedeutungen aus ihrem Training in einer großen Karte verzeichnet hat – und jedes Embedding bezeichnet gewissermaßen einen Ort auf dieser Karte, auf der die KI jetzt für jeden Text-Schipsel ein Fähnchen stecken. Wenn ich eine Frage stelle, verwandelt die KI diese Frage wiederum in eine Ortsangabe, schaut sich die Fähnchen in der Umgebung des Ortes an und sammelt die zugehörigen Textschnipsel ein.

Verba geht etwas cleverer vor als die Assistenten von OpenAI – die Arbeitsweise lasse ich mir von Edward erklären, der das Tool programmiert hat. Ich habe ihn vor vielen Jahren bei einem Workshop kennen gelernt und bin über seine Linkedin-Posts auf das Tool aufmerksam geworden. Weil ich seine Kontaktdaten schon hatte, konnte ich ihn mit meinen Fragen behelligen, was ich schamlos ausgenützt habe.
OpenAI scheint feste Grenzwerte zu haben für die Anzahl der Schnipsel und den Umkreis, in dem es sucht. Verba bestimmt dynamisch, wie viele Schnipsel einen engeren Bezug zur Frage haben. Die werden dann allesamt an die KI übergeben – das kann das neue GPT-4o von OpenAI sein oder ein lokales Sprachmodell wie Mixtral – die dann daraus eine Antwort erzeugt.
Unter dem Strich gibt mir das ein Werkzeug, mit dem ich große Mengen Material schnell und sinnvoll auswerten kann – kommt ja im Journalismus häufiger mal vor. Details zur Installation dann wie gesagt im Werkstattbericht.
Was nicht so gut funktioniert
Aber Vorsicht. „Ich habe jetzt eine schlaue Maschine, die für mich alles liest und versteht?“ Nicht so schnell, junger Padawan. Ich muss an dieser Stelle vielleicht auch nochmal eine Eigenschaft von heutigen KI-Sprachmodellen wie GPT-4 betonen: Die KI lernt nichts dazu. Anders als wir Menschen, die ja aus jedem Gespräch mit einem leicht veränderten Gehirn gehen. Deshalb muss ich diesen ganzen Aufwand mit den Schnipseln, der mentalen Karte und der Suche doch überhaupt nur treiben!
Diese Technik hat aber prinzipbedingt ein paar heftige Einschränkungen, die sich auch bei der „Verurteilt!“-KI schnell gezeigt haben. Das hier kann ein RAG-Assistent wie Verba – oder ein GPTs von OpenAI – derzeit nicht:
- Zählen. Mit der Frage: „Wie oft wurde im Podcast gemordet?“ kann man die KI regelmäßig blamieren. Zählen ist etwas, das Sprachmodelle ohnehin nicht so gut können – und dann beachtet die KI nie alle Schnipsel, die einen Bezug zum Thema haben. Vollständigkeit sollte man von einem RAG-Assistenten nicht erwarten. Und da die KI-Ergebnisse auch hier stark zufallsabhängig sind – wir sprachen darüber – fehlen immer wieder Stellen, an denen das Thema behandelt wurde.
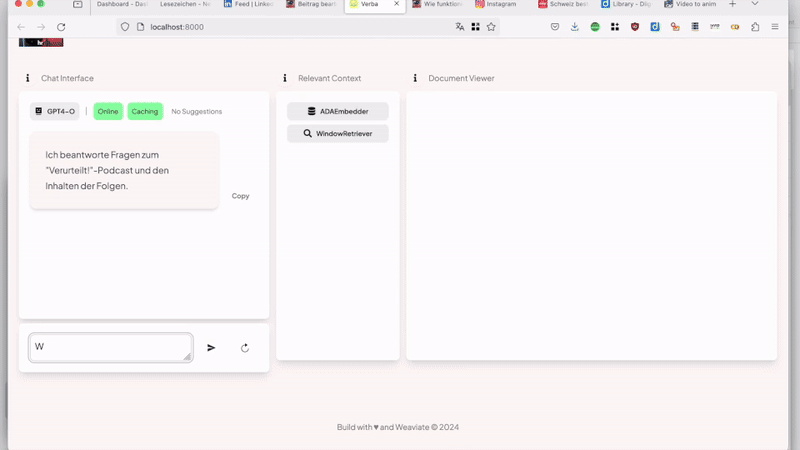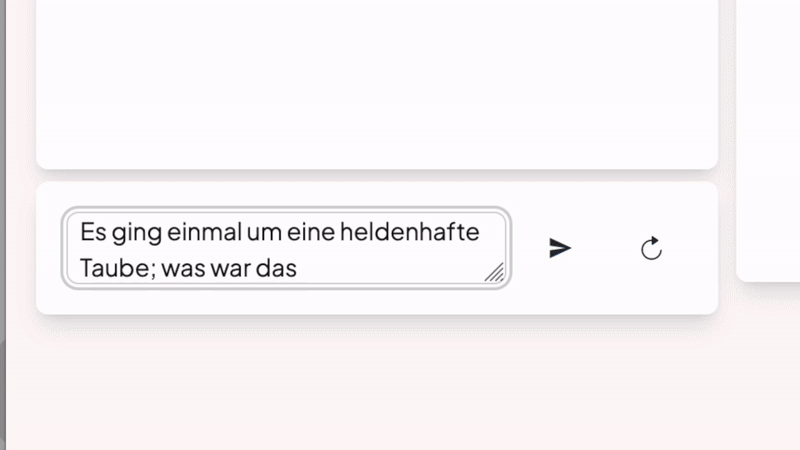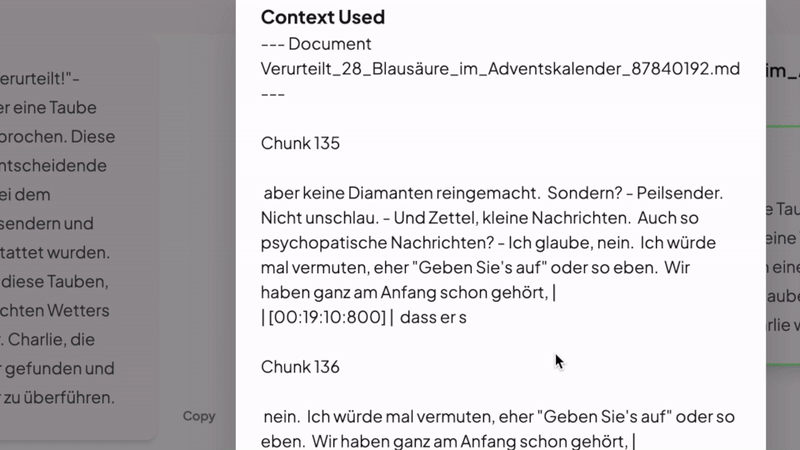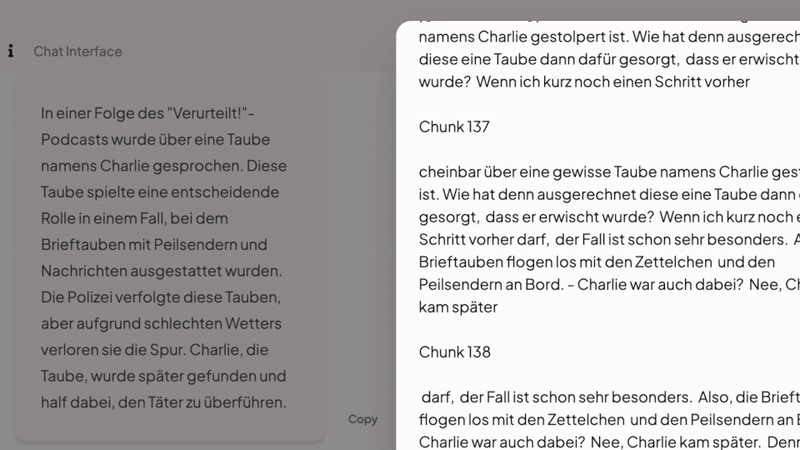
- Den Kontext des jeweiligen Dokuments erfassen. Wenn die KI Schnipsel gesucht hat, in denen es um Charly, die Heldentaube geht, „weiß“ sie nicht, worum es in der zugehörigen Podcast-Folge ging – um einen Produkterpresser – wenn das nicht zufällig in einem der gefundenen Schnipsel erwähnt wird. Deshalb sollen die Text-Schnipsel in einer zukünftigen Verba-Variante Metadaten mitbekommen; das könnte in unserem Beispiel die Inhaltsangabe der jeweiligen Podcast-Folge sein. Edward hat versprochen, dass er das umsetzen wird, wie viele andere gute Ideen, mit denen man die Leistung des KI-Assistenten weiter verbessern kann.
- Größere Strukturen erkennen. Man kann die KI nicht nutzen, um sich beispielsweise das dreiteilige Special rund um das Schicksal eines Verbrechensopfers zusammenfassen zu lassen. Oder der KI Tolstois Romanschwarte „Krieg und Frieden“ zu geben und zu sagen: lies es für mich und schreib mir dann den Aufsatz darüber.
Ohnehin sollten wir über die letzte Idee nochmal reden.

Was, wenn wir alle langen Texte nur noch von der KI lesen lassen? Eine schlimme Vorstellung.
Die Versuchung ist enorm, gerade wenn die Zeit und die Kraft im Redaktionsalltag nicht reichen, um alles gründlich durchzuarbeiten: Warum vier Seiten lesen, wenn ich mir von der KI statt dessen vier Stichpunkte geben lassen kann? Der KI- und Internet-Versteher Seth Godin hat diese provokante Frage gerade in einem kleinen Essay gestellt, in dem er von der „Arroganz des tl;dr:“ spricht und vor einer „Dopamin-Kultur“ warnt, die sich die Mühe des Verstehens nicht mehr machen will – oder kann.
Und dass KI auch häufig patzt – und beispielsweise Informationen zur Wahl haarsträubend falsch wiedergeben kann (Recherche von mir für hessenschau.de) – wissen wir nur zu gut.
Das kann in unserem Job, dem Journalismus, zu ziemlich verheerenden Fehlern führen. Fehlern, nach denen sich Nutzerinnen und Nutzer zu Recht fragen würden: Wozu brauchen wir euch denn überhaupt noch? Das kriegen wir auch von der KI direkt.
Schon deshalb darf man sich die Arbeit von RAG-Assistenten genau anschauen, Quellen überprüfen, Kontexte verstehen.
Verba gibt einem hervorragende Mittel, die Arbeit der KI nicht nur produktiv zu nutzen, sondern auch, sie zu überprüfen. Man muss es dann eben nur machen.
Auch lesenswert:
- Liebe Kollegas, baut Chatbots!
- Fallstudie: Ein Community-Management-Chatbot mit Fachwissen – und ein nützliches kleines Tool!
- Custom GPTs aus Europa für lau: Mistral kann jetzt Chatbots mit Spezialistenwissen!
Schreibe einen Kommentar