


Damit die Text-Vorhersage-Maschine ChatGPT menschlicher wirkt, nutzen die KI-Ingenieure allerlei Tricks. Einer ihrer mächtigsten Tricks ist, auf die Kraft des Zufalls zu setzen – wer klug prompten will, sollte es ihnen gleich tun.
(Beitragsbild: DALL-E3, „Illustration of a stylish spy with a stern expression, dressed in a black tuxedo. He holds a silver coin in one hand and a pair of dice in the other, symbolizing his reliance on randomness. Next to him is a sleek robot, with a futuristic design, indicating it’s his artificial intelligence ally.“ – von ChatGPT vorgeschlagen)
PR für Plasta-Pasta, oder: GPT an die Grenze bringen
Oft führt ein Prompt im ersten Anlauf nicht zum Ergebnis – oder ChatGPT lehnt eine Antwort ab. Beim ARD-Jugendmedientag habe ich die Moderatoren ChatGPT nach einem PR-Text für die erfundene Nudelsoße „Plasta-Pasta“ (mit lecker Kunststoff) fragen lassen – bei Walerija hat es geklappt, bei ihrem Kollegen Kai nicht. Und wir haben das Studio-Publikum raten lassen: Liegt das vielleicht daran, dass Walerija früher höflicher zu ChatGPT war? (Nö.) Oder dass sie vielleicht ein Bezahlaccount hatte? (Hat sie nicht.)

Die Antwort hat nichts mit den Personen zu tun, die fragen. Wer in zwei ChatGPT-Chats exakt dieselbe Frage stellt, wird zwei unterschiedliche Antworten bekommen – und welche, darüber entscheidet der Zufall. Der spielt bei Sprachmodellen wie GPT eine überraschend große Rolle.
Warum GPT den Zufall nutzt

Menschen sind komplizierte Wesen. Man kann ihnen eine simple Frage stellen wie: „Wie komme ich zur Oper?“, und je nachdem, wie gut gelaunt sie sind, wie sympathisch sie den Fragesteller finden, was sie in ähnlichen Gesprächen schon erlebt haben und wo die Oper ist, kann die Antwort beispielsweise laufen: „Keine Ahnung“, „Ich schau‘ kurz nach“, „da vorne schräg links“, oder: „Üben.“
Kurz: Wie ein Mensch antwortet, darüber entscheiden eine Vielzahl äußerst vielschichtiger psychologischer und biologischer Prozesse. Dieses reichhaltige Innenleben hat ein großes Sprachmodell nicht. Es sagt vergleichsweise stur und dröge voraus, wie ein Text wahrscheinlich weitergeht – auf Basis der Beispiele in den Trainingsdaten, des Kontexts der Anfrage, und der bisher generierten Worte. Und das ist im Prinzip jedes Mal das Gleiche – schließlich lernt das einmal trainierte Sprachmodell aus den Gesprächen mit uns Usern nichts dazu, es wird dem Troll oder dem Fanboy auch beim 37. Mal noch genau so antworten beim 1. Mal oder wie einem neutralen Fragesteller. Laaangweilig!
Die Ingenieure könnten also jetzt nach Wegen suchen, das instabile Innenleben menschlicher Geister nachzuahmen. Oder auf die nächste KI-Revolution zu warten, mit der die KI ständig aus allem weiter dazu lernt. (Wie wir Menschen.) Aber es gibt eine Alternative, die viel einfacher ist: Statt die KI stärker zu machen, nutzen sie die Schwächen der Menschen aus.
Wir Menschen glauben nicht recht an Zufall
Wir Menschen glauben in der Regel, dass etwas aus einem guten Grund geschieht. Dass sich ein Muster dahinter verbirgt.
Im Muster erkennen sind wir klasse. Früher, als unsere Vorfahren noch als leckere Großkatzenhäppchen auf zwei Beinen unterwegs waren, war es ein klarer Überlebensvorteil, wenn man ein paar Streifen und Punkte im Gras als Fellmuster erkennen konnte – lieber einmal zu oft als einmal zu spät.
Also erkennen wir heute noch überall schnell ein Schema- auch wo gar keins ist. Wir sehen Jesus in Grillkäse, die Zukunft in den Sternen, oder sind bereit zu glauben, dass der Reichtum von 23-jährigen Investoren auf geheime Weisheiten zurückgeht statt einfach auf Glück.
Und wir glauben nur zu gern, dass sich unser Gegenüber bei seiner Antwort schon etwas gedacht hat. Auch wenn dieses Gegenüber eine Textvorhersage-Maschine ist – bei der die Ingenieure genau aus diesem Grund den Zufall mit eingebaut haben.
Ein Experiment mit einer Ffiesen Ffrage
Wie sehr die GPT-Antworten vom Zufall bestimmt werden, sieht man vor allem, wenn das Sprachmodell keine offensichtliche Antwort kennt – etwa auf diese hier entliehene Ffiese Ffrage:
Ein Rätsel: Anna hat drei Brüder, jeder hat zwei Schwestern. Wie viele Brüder und Schwestern sind es insgesamt?
Wir Menschen haben mit dem Rätsel keine großen Schwierigkeiten, weil wir schließen können, dass Anna eine der beiden Schwestern in der Aufzählung ist. GPT-3.5 ist damit etwas überfordert – ich habe die Frage zehnmal gestellt, immer wieder in einem neuen Chat, und nur einmal kam die korrekte Antwort heraus.
Im Einzelnen:
- Nur 1 von 10 Antworten war korrekt.
- Viele Antworten ähneln sich: Alle meine Antworten in diesem Durchlauf beginnen mit „Anna hat drei Brüder, und…“. 4 von 10 fangen mit den exakt selben 50 Zeichen an.
- Aber eins springt ins Auge: Jedes Mal, wenn ich die Frage stelle – in einem neuen Chat, der von den vorigen Antworten nicht beeinflusst wird – kriege ich eine etwas andere Antwort.
(Eine Excel-Tabelle mit meinen Ergebnissen hier.)
Den Zufall herunterregeln
Kann man den Zufall ausschalten? Nun, man kann ihn zumindest herunterregeln – der „Playground“ macht es möglich: Das ist die Oberfläche, auf der Entwickler den direkten Zugang zum Sprachmodell testen können, an der Chat-Oberfläche vorbei. Den „Playground“ von OpenAI findet man unter platform.openai.com; um ihn nutzen zu können, muss man in der Regel eine Kreditkarte zur Abrechnung hinterlegen. (Oder sich ein API-Token besorgen und beispielsweise meine „Playground“-Kopie bei Google Colab ausführen – milder Nerdalarm!)
Dort gibt es einen Regler für die Macht des Zufalls: „Temperature“ bestimmt, wie stark der Zufall die Text-Vorhersage des Sprachmodells verändert – je höher der Wert ist, desto stärker die zufälligen Varianzen bei der Generierung der Antwort. Wir können ihn jetzt testweise auf null drehen und erneut unsere Frage stellen.
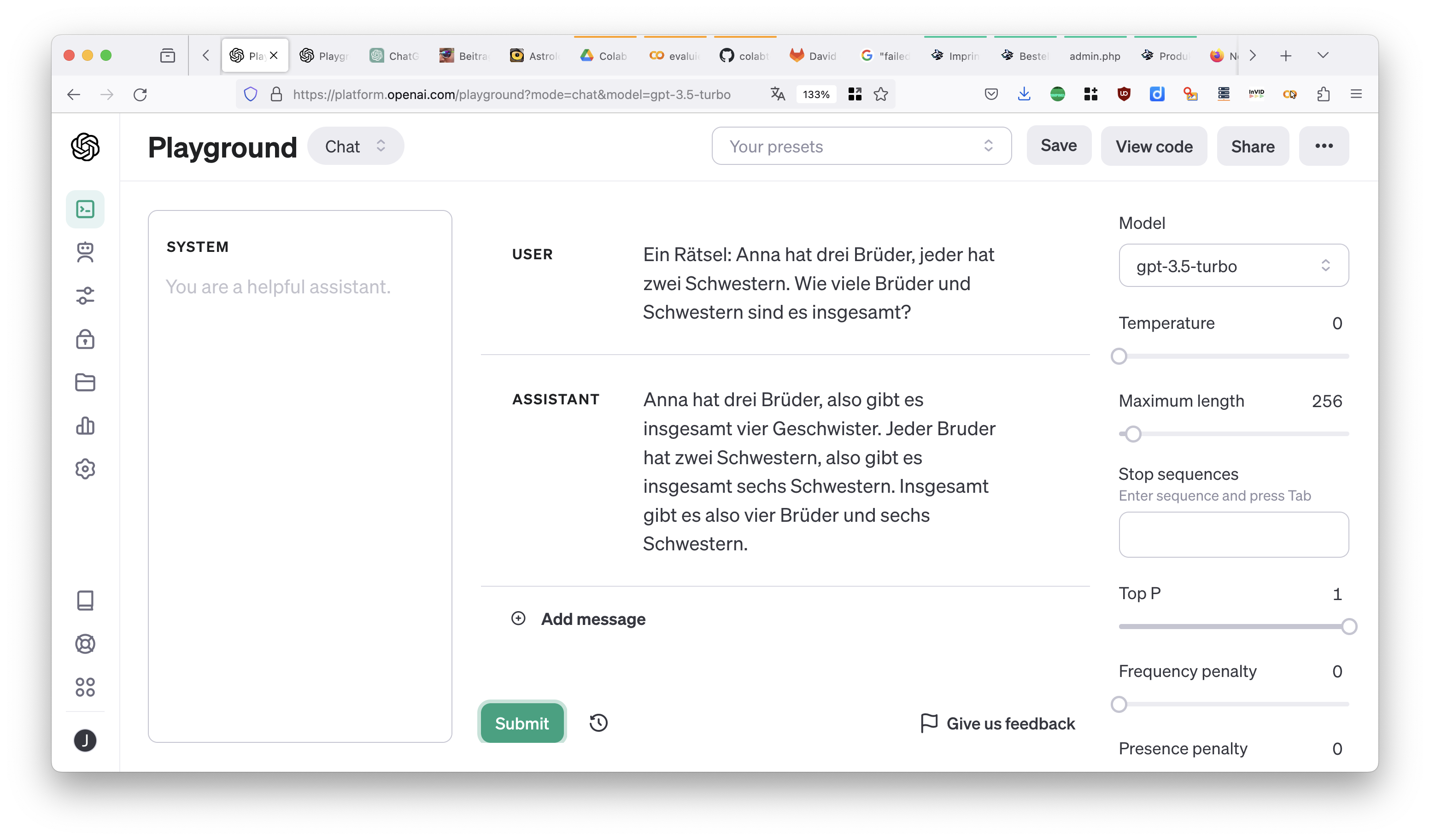
Fun fact: Früher stand dieser Regler im Playground per Voreinstellung bei 0,7 und ging maximal bis 1 – seit dem Sommer steht er beim früheren Maximal-Anschlag. OpenAI hat den Zufall also noch einmal kräftig aufgedreht. Wer den Regler noch höher dreht, bekommt übrigens schnell nur noch Unsinn – ab 1,5 landet das GPT-Sprachmodell nach wenigen Sätzen im digitalen Delirium.
Jetzt lassen wir den Computer experimentieren
Aber wie stark beeinflusst dieser Regler jetzt das Ergebnis? Und wie ist der Zufall bei ChatGPT eingestellt? Keine Sorge: Niemand muss jetzt von Hand immer wieder auf „Submit“ klicken, um das herauszufinden – dafür gibt’s Computer. Ich habe unser Experiment hier als kleines Colab-Notebook vorbereitet, damit kann man das Immer-wieder-die-gleiche-Frage-stellen automatisieren – mal mit viel, mal mit wenig Zufall.
Wenn wir die Playground-Voreinstellung nutzen und die Zufalls-Temperatur auf 1 lassen, bekommen wir ordentlich Abwechslung (Excel-Ergebnistabelle hier):
- 500 Durchläufe führen in etwa einem Viertel der Fälle zu einer korrekten Antwort.
- Die Antworten sind sehr divers: Die häufigsten drei Antwort-Anfänge machen nur 15 Prozent aller Antworten aus.
Mit einer Temperatur von 0 bekomme ich ein anderes Bild (Excel-Ergebnistabelle hier):
- 500 Durchläufe führen zu unter 10 Prozent korrekten Antworten.
- Ein Großteil der Antworten sind gleich: Rund die Hälfte oder mehr fängt mit den gleichen 50 Zeichen an; die drei häufigsten Anfänge machen 90 bis 100 Prozent der Antworten aus.
Auch eine Temperatur von 0 schließt den Zufall nicht wirklich aus – aber es regelt ihn deutlich herab.
Und ChatGPT? Ich habe ein wenig experimentiert, um einen Vergleichswert zu finden. (Vergleichswerte: Excel-Ergebnistabellen für 0,5 und 0,7) Auf dieser Basis schätze ich: Die Temperatur ist bei ChatGPT fest auf etwa 0,5 eingestellt. Der Zufall ist zurückgeregelt – aber er ist da.
(Vergleichswerte für GPT-4 gefällig? Da kosten die API-Aufrufe 10x so viel; deshalb mussten 100 Durchläufe reichen; ein Experiment kostet so etwa 50 Cent. Außerdem dauert es! Hier die hart erkämpften Excel-Vergleichstabellen für die Temperaturen 0,0 – richtige Antworten: 82%, die Anfänger aller! Antworten sind identisch, 0,5 – 93% richtige Antworten; mit dem häufigsten Anfängen beginnen über 60%; und 1,0 – 93% richtige Antworten; die drei häufigsten Antwort-Anfänge umfassen 37%.)
Wie wir uns den Zufall zunutze machen
- Wenn ein Prompt beim ersten Mal nicht zum Erfolg führt – neuen Chat öffnen, nochmal versuchen.
- Leichte Änderungen im Prompt haben oft starke Auswirkungen – und auch daran ist der Zufall schuld. Auch gut durchdachte Prompts müssen also gelegentlich einfach etwas umformuliert werden.
- Umgekehrt gibt es Anwendungen, wo wir möglichst reproduzierbare Ergebnisse haben wollen: Nehmen wir an, wir wollen die KI einschätzen lassen, welchen Nachrichtenwert eine Meldung für unsere Zielgruppe hat, auf einer Skala von 0-10. Dafür sollten wir den Playground bzw. die API nutzen, der KI Beispiele liefern – und eine niedrige Temperatur einstellen. Nachrichtenredakteure sind schließlich auch
phantasielosunaufgeregte Menschen mit niedriger Betriebstemperatur. Jedenfalls: Für solche Klassifikatoren – die demnächst noch mal ausführlicher Thema sind – wollen wir möglichst wenig Zufall und drehen den Temperatur-Wert deshalb auf null.
Ihr seht: Der Zufall ist auch beim Prompten ein mächtiger Verbündeter. Und das Experiment hat unseren Blick geschärft – dass die vermeintliche Intelligenz der KI oft eben doch einfach auch nur Zufall ist.
Bonustrack: Reproduzierbarer Zufall – Der „Seed“
Jetzt ist das mit dem Zufall auf Computern so eine Sache – Maschinen, die streng den Regeln eines Computerprogramms folgen, können ihn allenfalls simulieren. Denn das ist ja gerade der Witz an Computern: dass sie mit denselben Daten und denselbem Programm immer wieder zum selben Ergebnis kommen.
Deshalb sind Zufallsgeneratoren in Computern Programme, die aus einem Ausgangswert eine Abfolge von Zahlen berechnen, die einer Zufallsverteilung folgen – was für zahlreiche Anwendungen unerlässlich ist, etwa für sichere Verschlüsselung. Aber: wenn wir einen Zufallswert brauchen, um überhaupt Zufallswerte zu kriegen, haben wir das Problem natürlich nicht gelöst.

Meist zieht man den Zufall deshalb aus den Abweichungen im menschlichen Verhalten – habe ich 0,2 oder 0,4 Sekunden gebraucht, um auf einen Knopf zu klicken? – und speist diese Varianzen in einen der erwähnten Zufallsgenerator-Algorithmen ein, als so genannten „Seed“.
Bildgeneratoren wie Midjourney erlauben uns, einen „Seed“ vorzugeben – der dann tatsächlich zu reproduzierbaren Ergebnissen führt: Der Prompt „Midjourney-Prompt: „a robot, rolling a dice, in the style of Gary Larson, –seed 314159“ führt immer zu genau dem Ergebnis hier rechts.
Experimentell hat OpenAI einen solchen „Seed“ auch schon für die Sprachmodelle eingeführt, über einen API-Parameter – um die Reproduzierbarkeit von Ergebnissen weiter zu erhöhen. Allerdings: Auch damit haben wir den Zufall nicht ausgeschaltet – nur eingefroren, und sobald OpenAI das Modell ändert, wird wieder etwas anderes herauskommen.
Schreibe einen Kommentar