


Was ich so 2023 getan habe: vor allem viele, viele KI-Seminare gegeben. Welche Frage ich da immer wieder gehört habe: Wo gibt’s ein gutes kostenloses KI-Transkriptionstool? Weil ich das nicht richtig beantworten konnte, hab’ ich euch eins gebastelt.
Bild: Midjourney, “a high-tech gift package, surprise, joy”
“Wo Transkription?” Die Frage liegt ja nahe. Ich konnte sie aber nicht so richtig beantworten. Zum einen habe ich als ARD-Mitarbeiter Zugriff auf ein schön einfaches Transkriptionstool namens “SAM”. Das nutzt ein Modell des Fraunhofer IAIS und funktioniert ganz ordentlich. Zum anderen dachte ich: es gibt doch Whisper.
Whisper ist ein KI-Modell von OpenAI. Und anders als die großen Text- und Bildgenerierungs-Modelle von OpenAI, GPT-3ff. und DALL-E, kann man den Whisper-Code bei Github finden und auf eigenen Rechnern laufen lassen, ohne Kosten. Es mag heimlich unter anderem mit der Arbeit der ZDF-Untertitel-Redaktion aufgebaut worden sein – aber es ist immerhin “Open Source”, und es funktioniert gut. Wie gut Whisper funktioniert, hatte ich bei einem meiner ersten großen Sprachmodell-Aha-Momente erlebt – als ich mir mit Erfolg ein kleines Skript gebastelt hatte, das mir 20 Stunden Youtube-Videos verschriftlichte und zusammenfasste.
Allerdings: Whisper gibt es quasi nur roh – als Python-Programmbibliothek, die man in eigene Programmier-Projekte einbinden kann. Bis jetzt habe ich keine einfache Adresse gefunden, wo man Whisper direkt zum Verschriftlichen nutzen kann. Selbst die Bezahl-Variante von ChatGPT patzt – obwohl das Sprachmodell GPT-4 dort prinzipiell Zugang zu einem Whisper-Dienst hat, scheitert die Transkription gerne am falschen Audio-Datei-Format.
Gibt’s denn keinen einfacheren Weg? Meiner ist jetzt ein bisschen einfacher: Ich habe ein supereinfaches Transkriptions-Colab-Notebook gebastelt. Alles, was man braucht, sind Audiodateien, ein Rechner mit Internet-Zugang – und ein Nutzerkonto bei Google (bzw. Gmail, Youtube, Android, Maps, Circles – was auch immer).
Und man muss keinerlei technisches Fachwissen mitbringen.
Wie man ein Colab-Notebook nutzt
Colab ist super! Kleine Einführung für alle, die bisher nie eins genutzt haben: Das ist eine standardisierte, einfache Python-Umgebung, die in der Google-Cloud läuft, und die man dort – nach beliebiger Google-Anmeldung – kostenlos nutzen kann. Aus Nutzersicht ist das wie ein Programm, das im Browser läuft – man muss nichts installieren, braucht keine Extra-Software.
Colab nutzt einen besonderen Dokumenttyp namens “Notebook”, das ist eine Kombination aus Textblöcken und ausführbarem Programmcode. Ein solches Notebook-Dokument habe ich bei Github abgelegt. Was man als Nutzerin nur tun muss: es in Colab laden, ausführen – und eine Audiodatei zum Wandeln hochladen.
Schritt für Schritt: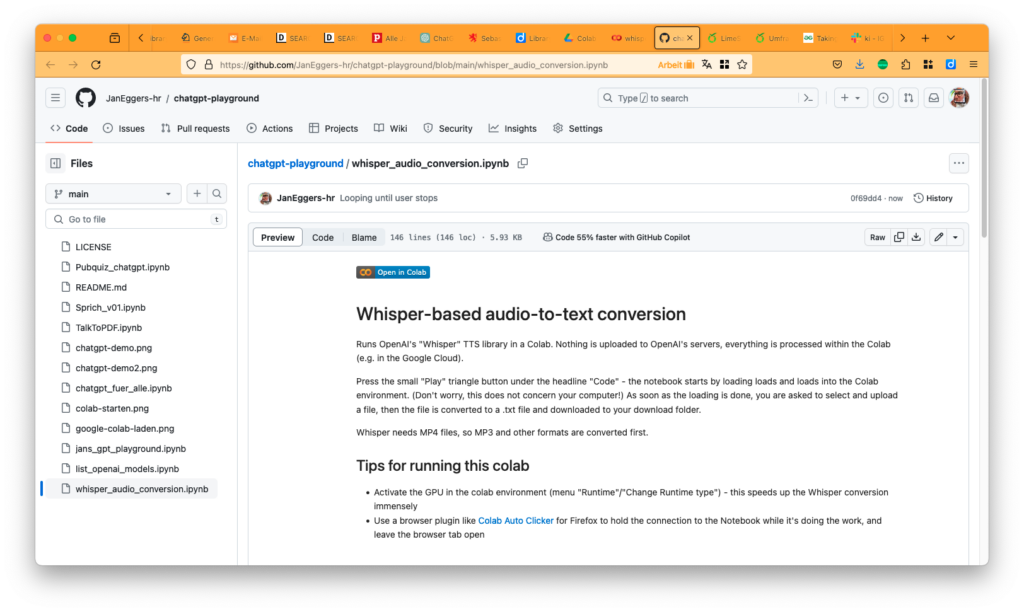
- Den Link auf mein Notebook bei Github aufrufen. Das sieht dann aus wie auf dem Bild oben: man bekommt eine Textdatei angezeigt, die auch einen großen Programmcode-Block enthält (und den man ignorieren darf).
- “Open in Colab”-Schaltfläche klicken. Das war in den Seminaren übrigens immer die größte Hürde: diesen Knopf finden! Tipp: er ist blaugrün… direkt über der Überschrift “Whisper-based…”
- Google Colab öffnet sich – mit dem Notebook. Der böse Programmcode ist versteckt – und ein Google-Coprozessor ist auch schon aktiviert: er sorgt dafür, dass alles viel, viel schneller geht. Falls nicht: Hier im Colab-Menü unter “Laufzeit” den Punkt “Laufzeittyp ändern” aufrufen und eine GPU anwählen.
- Jetzt auf den kleinen “Abspielen”-Button links neben dem Text “Code Anzeigen” klicken. Den zu finden ist wieder eine Hürde – liebe Mitnerds, nicht überheblich werden: Zu viel IT versetzt normale Menschen in leichte Panik, die dazu führt, dass sie kleine Schaltflächen schon mal übersehen.
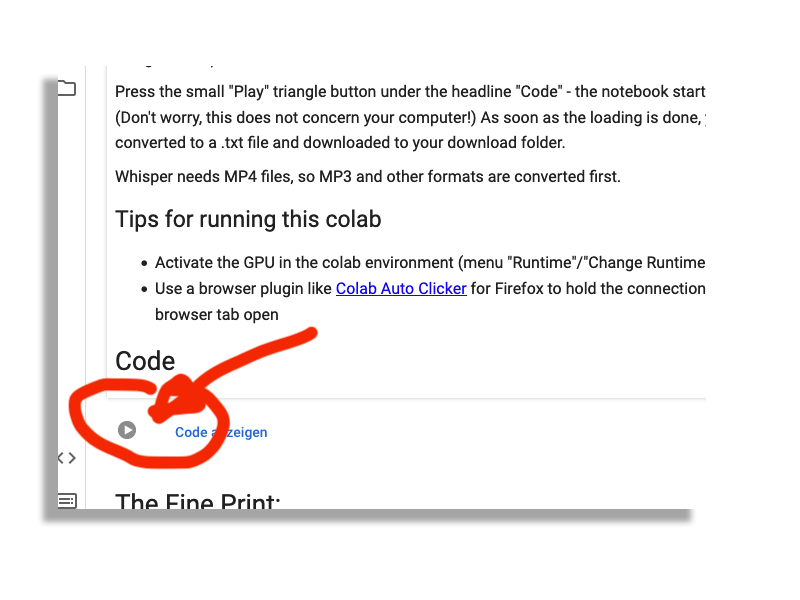
- Die Warnung wegklicken, die darauf hinweist, dass der Code nicht von Google kommt. (Und die letztlich besagt: Vertraue ich demjenigen, der das Programm geschrieben hat, wirklich? Es könnte ja beispielsweise alle meine Daten per Mail irgendwo hinschicken… aber wer in meinen Code schaut, kann sich schnell überzeugen: alles harmlos.)
- Modellgröße (small, medium, large) und Ausgabeformat wählen. Oder einfach so lassen.
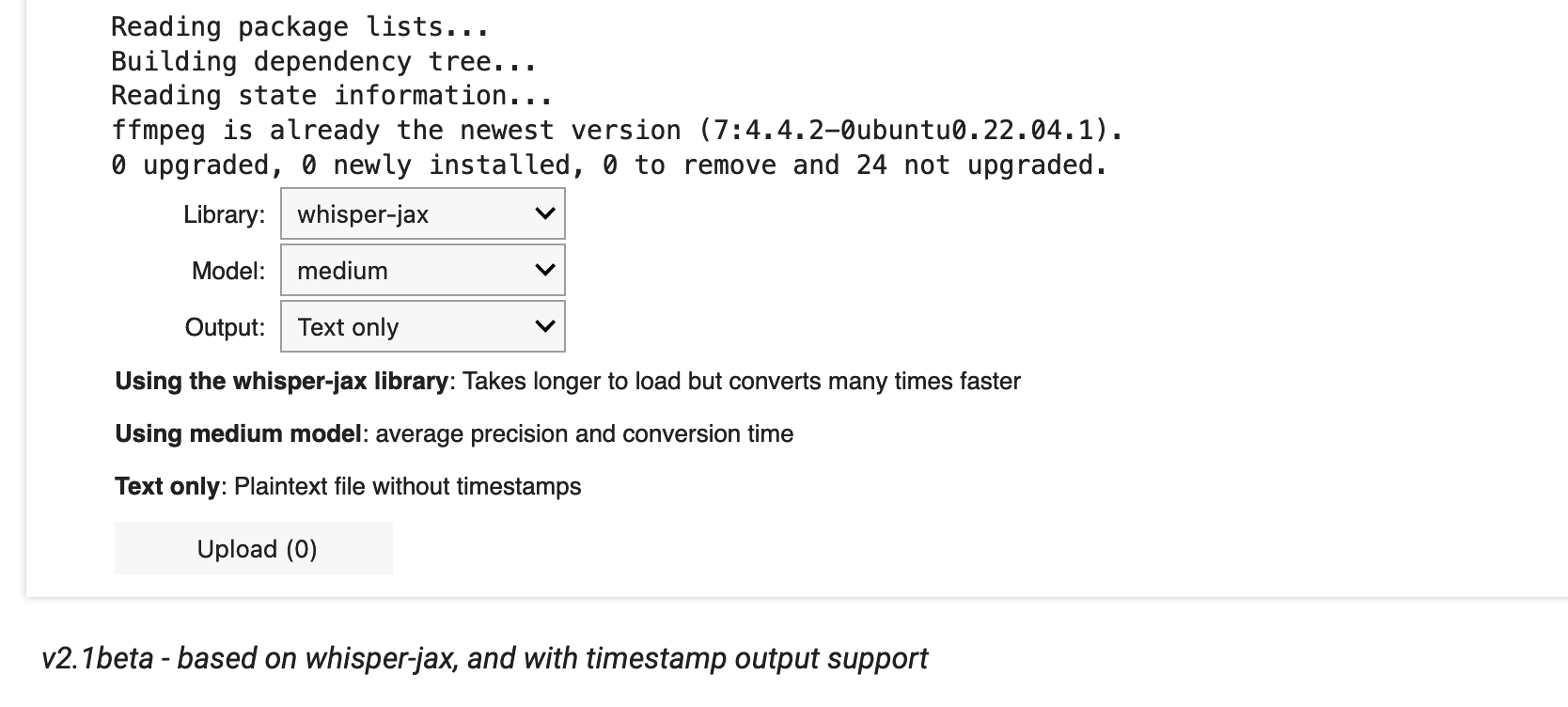
- Auf den “Upload”-Knopf klicken und einen oder mehrere Audiodateien auswählen. (Dauert manchmal eine Sekunde, bis das Programm loslegt – bitte Geduld!)
- Eine Weile warten, während das Programm die nötigen Programm-Zusatzmodule herunterlädt – und das eigentliche Modell: Die Gewichte für das neuronale Netzwerk, das die gesprochenen Worte in Buchstaben verwandelt, benötigen etwa 5 Gigabyte Platz. Zum Glück alles Daten, die direkt in die Google-Cloud fließen und nicht meine lokale Internetverbindung belasten.
- Nach ein paar Sekunden/Minuten landet die Transkription als Textdatei im Download-Ordner meines PCs. (Bzw. als CSV-Datei, die ich mit einem Tabellenprogramm öffnen kann und die neben den Texten auch noch Timecodes enthält.)
Wie lang es dauert: An sich arbeitet Whisper selbst mit Koprozessor fast so lang, wie das Audio läuft – dank einer weiterentwickelten Programmbibliothek namens whisper-jax konvertiert das kleine Programm das Audio mehrere dutzende Male schneller. (Sie braucht allerdings etwas länger, um geladen zu werden.) Wenn alle Daten bereit liegen, ist das Ergebnis in der Regel in ein paar Dutzend Sekunden fertig und wird heruntergeladen.
Wer übrigens lieber was Gekauftes hätte als was Selbstgebasteltes (BUH!), findet hier eine Demo-Installation von whisper-jax auf Huggingface. Die ist von richtigen Programmierern.
Und jetzt: festliches Transkribieren!

Und der Datenschutz?
Hmmmnunja. Streng genommen landen alle Audios, die man verarbeitet, in einem Ordner in dem Google Colab und damit in der Google-Cloud. Allerdings: Google löscht die Colabs nach Gebrauch – und von den Audio- oder Text-Daten wird nichts an OpenAI übertragen. Die große Enthüllungs-Geschichte mit dem NSA-Whistleblower würde ich damit vielleicht nicht transkribieren, aber sonst….
…wer maximale Sicherheit will, darf das Notebook auch gerne in einer Jupyter-Umgebung auf dem eigenen Rechner ausführen, dann fließen überhaupt keine Daten in Clouds.
Auch lesenswert:
- Kann ich KI für mich den Stuckrad-Barre lesen lassen?
- Quickie: So schreibt die KI deinen Programmcode mit!
- Wie funktionieren die GPTs – die neuen KI-Assistenten?
Schreibe einen Kommentar