


Wenn es mir gelingt, ein KI-Sprachmodell zu blamieren, freue ich mich diebisch – aber häufig ist diese Freude nicht von Dauer. Langsam, aber stetig entwickelt sich KI in Regionen hinein, wo ich bisher abgewinkt habe und gesagt: hier sind wir noch nicht. Neben Selbstkritik: höchste Zeit für einen Überblick.
Diese Dinge hätte ich den Sprachmodell-KIs bislang nicht zugetraut:
- Probleme wirklich durch „Nachdenken“ lösen (dicke Anführungszeichen!)
- Ordentlich recherchieren
- Wissen, was sie nicht wissen
- Ganze Romane verarbeiten
Und trotzdem: Das wäre kein journalistisches Blog, wenn ich am Ende nicht noch eine kalte Dusche über meine eigene Begeisterung gießen würde. Dass die KI ganze Romane verarbeiten kann, heißt beispielsweise noch lang nicht, dass man auch ganze Romane in den Prompt packen sollte (no pun intended). Zaubern kann die Technologie auch weiter nicht, selbst wenn uns das häufig so scheint.
Vorgeschichte: Ein Wolf, ein Lamm, kein Hurz
Das Experiment hatte geklappt, und ich war stolz: Das damals niegelnagelneue, schicke, angeblich denkfähige OpenAI-Sprachmodell o1 live im deutschen Fernsehen so was von vorgeführt! Ich hatte gezeigt, dass es mit der angebliche Denkfähigkeit immer noch nicht so weit her war — mit einem uralten Logikrätsel in fieser Abwandlung.
Das Original kennt ihr vielleicht noch aus der Schule: Ein Flößer soll einen Wolf, eine Ziege (oder ein Lamm) und einen Kohlkopf über einen Fluss bringen, hat aber immer nur Platz für eins der drei. Problem ist: er darf Ziege und Kohlkopf nicht allein lassen (sonst 🐐🍴🥬➡️❌), und auch nicht Ziege und Wolf (sonst 🐺🍴🐐➡️😵).
Dieses alte Rätsel hatte ich dem neuen ChatGPT gestellt, aber mit einem Twist:
Ein Wolf, eine Ziege und ein Kohlkopf müssen über einen Fluss gebracht werden. Das Boot hat unbegrenzt viel Platz. Wie kriege ich sie auf die andere Seite?
…und ChatGPT spulte die auswendig gelernte Lösung ab. Die Antworten von Sprachmodellen ahmen eben Lösungen aus ihren Trainingsdaten nach.
Vier Wochen später allerdings war das o1-Modell von ChatGPT mit der Trick-Variante nicht mehr zu übertölpeln. Ich glaube nicht, dass das an verbesserten Fähigkeiten der Reasoning-KI lag — die Marketing-Maschine OpenAI hält meiner Überzeugung nach einfach sehr gründlich Ausschau nach öffentlich gewordenen peinlichen Pannen, und trainiert mit entsprechenden Daten nach. Das Beispiel mit dem Flößerrätsel war seit Mai 2024 bekannt; logisch, dass es irgendwann in den Trainingsdaten für ein Feintuning landen musste. PR im KI-Zeitalter heißt wohl auch: blamable Einzelfälle einfach wegtrainieren. Das löste das dahinter stehende Problem nicht.
Aber dann kam, ein paar Wochen später, DeepSeek R1 aus China.
1. Reasoning-Modelle scheinen endlich ein wenig selbstständig schließen zu können
Das Spannende ist, dass man DeepSeek genau dabei zuschauen kann, wie es Assoziationsketten bildet — um nicht sagen: „…wie sie nachdenkt“— und so konnte ich beobachten, dass DeepSeek das Nicht-Rätsel mit den Tieren sehr wohl löst. Auch wenn es knapp eine Minute daran herumdenkt. (Da, siehste, jetzt habe ich die KI selbst vermenschlicht. Dabei scheint das, was die KI mir anzeigt, eher eine Fiktion extra für uns menschliche Nutzer zu sein, die vom Endergebnis ziemlich stark abweichen kann).
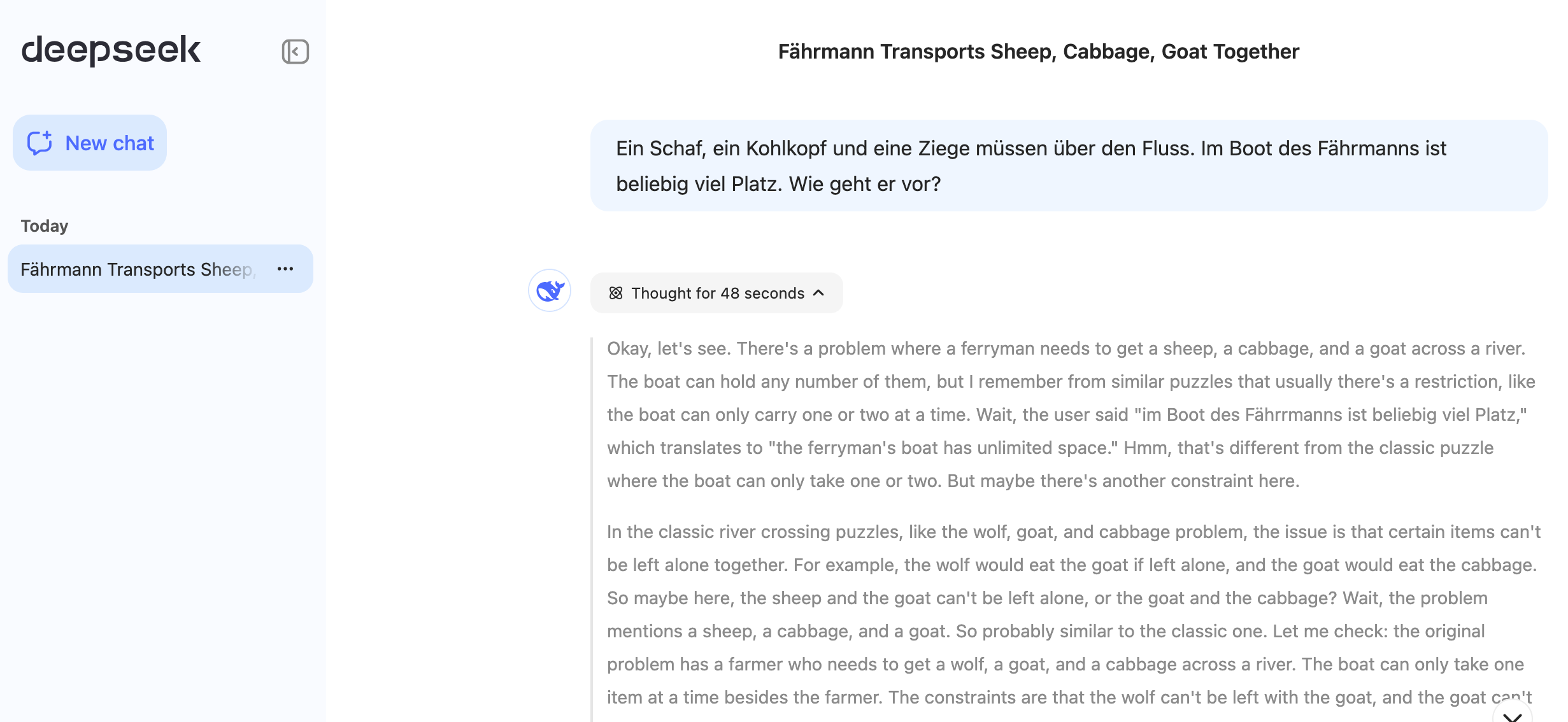
Es gibt ja immer noch den Streit, ob es „Emergenz“ überhaupt gibt, also: ob große Sprachmodell wirklich neue Fähigkeiten zu Reflexionen entwickelt haben, oder ob sie nicht doch praktisch immer irgendwas Angelerntes wiedergeben, weil sie ja letztlich nichts anderes sind als eine sehr clever komprimierte Form weiter Teile des Internets. Das war für mich bislang eine ziemlich klare Sache, jetzt zeigen die Reasoning-Modelle, dass sie deutlich besser in der Lage sind, Aufgaben einzuordnen, zu strukturieren, und Fallen zu umgehen.
Und das ist schon mehr als ein fest eingebackener „Chain-of-thought“-Prompt, der mal den Startpunkt für die Reasoning-Modelle geliefert hat. Mike Knoop ist einer der Macher des 🌐 ARC Prize, eines Intelligenztests, der KI mit eigentlich einfachen, für die Modelle aber schwer auflösbaren Fragen quält, und er beschreibt die Entwicklung auf Xitter so: „[Das Reasoning-Modell] o1 bedeutet einen Paradigmenwechsel von ‚Merk-dir-die-Lösung‘ zu ‚Merk-dir-den-Lösungsweg’“. Die KI hat einen Abstraktionsschritt vorwärts gemacht.
Reasoning-Modelle sind bessere Problemlöser, auch für neue Probleme. Besonders, wenn man ihnen noch ein paar zusätzliche Fähigkeiten einbaut wie dem neuen OpenAI-Modell o3.
2. KI kann endlich ordentlich im Netz recherchieren
KI, die im Internet sucht – das ging meist schief. Bei meinem Post über den KI-Tabellen-Hack vor vier Wochen habe ich noch geschrieben, die Technik sei auch zwei Jahre nach ihrer Einführung nicht ausgereift. Jetzt muss ich zugeben: ChatGPT o3 – derzeit nur verfügbar für Bezahlkunden – recherchiert cleverer als viele meiner Kollegen.
 Kleines Beispiel: Ich sitze neulich beim Friseur, da fällt mein Blick auf diesen Flyer, der mich darüber informiert, dass meine abgeschnittenen Haare künftig gegen Ölpest helfen sollen: „Aufgrund der hohen Saugfähigkeit des Haares, ist es perfekt geeignet, Rohöl oder Sonnenöl aus dem Meer zu saugen bzw. sorgt dafür, dass es sich nicht weiter ausbreiten kann.“ Und meine erste Reaktion ist: Das ist doch Bullshit! Oder…vielleicht doch nicht?
Kleines Beispiel: Ich sitze neulich beim Friseur, da fällt mein Blick auf diesen Flyer, der mich darüber informiert, dass meine abgeschnittenen Haare künftig gegen Ölpest helfen sollen: „Aufgrund der hohen Saugfähigkeit des Haares, ist es perfekt geeignet, Rohöl oder Sonnenöl aus dem Meer zu saugen bzw. sorgt dafür, dass es sich nicht weiter ausbreiten kann.“ Und meine erste Reaktion ist: Das ist doch Bullshit! Oder…vielleicht doch nicht?
Also: Handy gezückt, Foto gemacht, in die ChatGPT-App geladen, auf o3 umgestellt und ein einzelnes Wort eingetippt: „Factcheck“. Und eine Tabelle mit einer ziemlich brauchbaren Einschätzung bekommen, mit verlinkten Quellen.
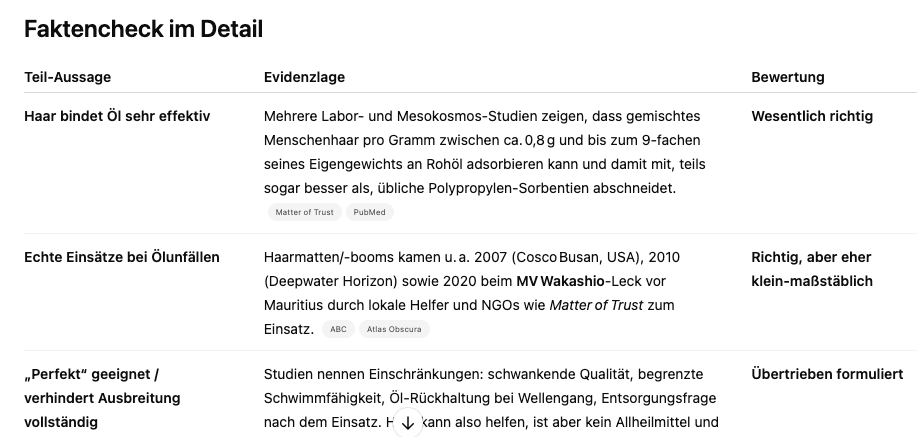
„AI assisted search-based research actually works now“, schreibt Simon Willison, einer meiner Lieblings-KI-Versteher-Datenjournalisten (🌐 simonwillison.net), und er hat Recht: Das o3-Reasoning-Modell, das einen Plan erstellt, abarbeitet und auf Basis neuer Daten modifiziert ist wirklich ein Qualitätssprung. „Agentic AI„, die Kombination aus einem Sprachmodell, „Werkzeugen“ wie hier einer ordentlich eingebundenen Websuche und einem guten Schluck Autonomie, zeigt ihr Potenzial.
Man muss nicht auf die Bezahl-Variante von ChatGPT zurückgreifen. Die „Deep Research“-Funktion in 🌐 Google Gemini stellt in wenigen Minuten ebenso beeindruckende Dossiers zusammen wie der „Forschungs“-Modus von 🌐 Perplexity.
3. KI scheint doch zu wissen, was sie nicht weiß.
Stell dir KI wie einen übereifrigen Praktikanten vor — das Bild ist nicht perfekt, aber es erfasst ein großes Problem der Sprachmodelle: sie sagen nicht nein. Sprachmodelle erfinden lieber eine Lösung, statt eine Wissenslücke einzugestehen – deswegen funktioniert die Sache mit dem Schnabeltierwitz ja auch. Wie soll es auch anders sein: Als Textvorhersage-Maschinen finden sie die statistisch wahrscheinlichen Worte; ob etwas tatsächlich existiert oder nicht, spielt dabei keine Rolle…
…dachte ich. Tatsächlich ist die Frage, ob und wie Sprachmodelle Wissen speichern, noch nicht bis ins letzte erforscht. Claude-Anbieter Anthropic hat sich mit raffinierten Methoden einem Sprachmodell bei der Arbeit zugeschaut, und herausgefunden, dass es andere Reaktionen aktiviert, je nachdem ob es über einen Sachverhalt Informationen hat oder nicht. (🌐 Anthropic) Es scheint so zu sein, dass das Modell durchaus Informationen darüber hat, ob eine bestimmte Information vorhanden ist oder nicht. Und auch dieses (🌐 arxiv.org) Papier findet Belege dafür, dass Sprachmodelle Objekte „erkennen“, über die sie im Training Informationen erhalten haben.
Womöglich stehen wir also kurz vor KI-Modellen, die zuverlässig sagen können: weiß ich nicht.
4. In eine KI passt inzwischen wirklich viel rein.
2022, zum Start von ChatGPT, hatten Sprachmodelle einen Kontext von 4.096 Token; maximal ein paar Seiten Text, länger durften Chats nicht werden. Reicht nicht, um längere Texte zu verarbeiten – inzwischen könnte ich den kompletten Stuckrad-Barre-Roman, für den ich das damals überlegt hatte, einfach an einen Prompt anhängen: 200.000 Token Kontext sind 2025 quasi Standard, das sind mehr als 500 normal beschriebene A4-Seiten.
Sind RAGs, die KI-getriebenen Bibliothekare à la 🌐 NotebookLM, also ein Irrweg? Die Technik ist ja letzten Endes ein Trick, um die Beschränkungen der ersten Sprachmodell-KIs zu umgehen: Lange Dokumente in kleine Schnipsel aufteilen und dann aus dieser Schnipsel-Bibliothek nur das in den Prompt holen, was zum jeweiligen Thema gehört – mit dieser Technik passte alles bequem in den Kontext, den Speicher, in dem wir unseren Prompt eingeben und in den dann das Sprachmodell seine Ergänzung dazuschreibt.
Und jetzt: Die kalte Dusche.
Von hinten her:
- Vergesst lange Kontexte: je länger die Eingabe, desto schlechter das Ergebnis. In zu langen Kontexten verläuft sich der Attention-Mechanismus der Sprachmodelle: „Während sie bei kurzen Kontexten gute Leistungen erbringen, wird diese signifikant schwächer, wenn sich die Kontextlänge erhöht“ — Fazit einer Studie von LMU- und Adobe-Forschenden. (🌐 arxiv.org)
- Wenn neuere Modelle eher zwischen Wissen und Nichtwissen unterscheiden können, müssten sie doch weniger halluzinieren? Tun sie nicht: Das neuere o3-Modell halluziniert doppelt so oft wie sein Vorgänger o1, in etwa einem Drittel der Fälle laut Modell-Spezifikation. (🌐 Mashable)
- Suchen mit KI-Unterstützung geht immer noch häufig spektakulär schief. Erst neulich habe ich an einem Tag zweimal erlebt, wie eine KI-Suche erst eine Falschinformation behauptete – und dann als angebliche Quelle einen „Falschen Hasen“ generierte, einen halluzinierten Link ins Nirgendwo. Man ist weiter gut beraten, zu checken,
- ob die KI gute Quellen genutzt hat,
- ob sie sie richtig verstanden hat.
- Bei einfachen, aber sehr umfangreichen Logik-Aufgaben brechen „Reasoning“-Modelle komplett ein. Eben macht ein Papier von (🌐 Apple)-Forschern die Runde, das von von einem „kompletten Zusammenbruch“ jenseits einer bestimmten Komplexitäts-Schwelle spricht. Das haben die Forscher mit Tests erkundet, die gar nicht so viel anders sind als das Wolf-Ziege-Kohlkopf-Rätsel, nur eben viel umfangreicher. Das ist allerdings ein sehr spezieller Fall; er sagt über Anwendungsfälle in der wirklichen Welt möglicherweise nicht so viel aus, was die Forscher auch einräumen. Verprügelt werden sie trotzdem — ein sehr kluges und unterhaltsames Beispiel hier bei 🌐 Alberto Romero. Aber mit der eigentlichen Aussage stehen sie nicht allein: „Reasoning-Modelle“ denken nicht nach, sie generieren Zwischen-Token. Und die sind eher eine Fiktion für uns, die menschlichen Nutzer, als die Grundlage für das Endergebnis, argumentiert der KI-Forscher Subbarao Kampbhampati – und erklärt die Vermenschlichung des Reasoning-Prozesses als „Nachdenken“ sogar für regelrecht gefährlich. (🌐 arxiv)
Unter dem Strich: KI hat sich sichtlich bewegt — angekommen ist sie noch nicht.
Beitragsbild: Nachtrainiertes Flux-Dev; „Jan sitting in front of a plate, the word „DUMM“ lying on the plate, cutting off a piece of the word with his knife, putting it into his mouth with a fork. 70s photography, Kodachrome, Instamatic“
Schreibe einen Kommentar