


Kleines Feiertagsgeschenk: Seit heute hat mein ChatGPT-Konto Zugriff auf die neuen Wunderfähigkeiten „Browsing“ und „Plugins“ der Sprach-KI – die Fähigkeit, Informationen im Internet zu suchen. Das ist tatsächlich ein gewaltiger Sprung – und ich vermute, dass dabei eine clevere Form der institutionalisierten Werksspionage eine entscheidende Rolle spielt.
Weiterlesen: GPT-4 surft selbst im Netz – warum das so eine große Sache istEine der kleinen Gemeinheiten, mit der ich ChatGPT gern bei Demos gequält habe, ist die Frage, wer denn eigentlich in Frankfurt Bürgermeisterin ist. Für alle, die gnäderweise nichts von der Frankfurter Stadtpolitik der letzten Monate mitbekommen haben: Der alte SPD-OB Peter Feldmann musste sich wegen einer Korruptionsaffäre einem Referendum stellen und wurde von den Bürgern aus dem Amt gejagt, und bis zur Neuwahl war Nargess Eskanderi-Grünberg, eine Grünen-Politikerin, kommissarisch Oberbürgermeisterin.
ChatGPT antwortete aber auf die Frage nach der Oberbürgermeisterin – oder auch schon mal nach dem Oberbürgermeister – gern mit: „Bernadette Weyland“. Sie war in der OB-Wahl 2018 die unterlegene CDU-Gegenkandidatin.
Das neue GPT-4-Modell ist nun darauf trainiert, zu merken, wann es eine Frage nicht aus den Trainingsdaten beantworten kann, und sich Informationen aus dem Netz zu holen. Es tut nichts, was wir nicht auch täten – es googlet. (Naja: eigentlich bingt es, mehr dazu später.)
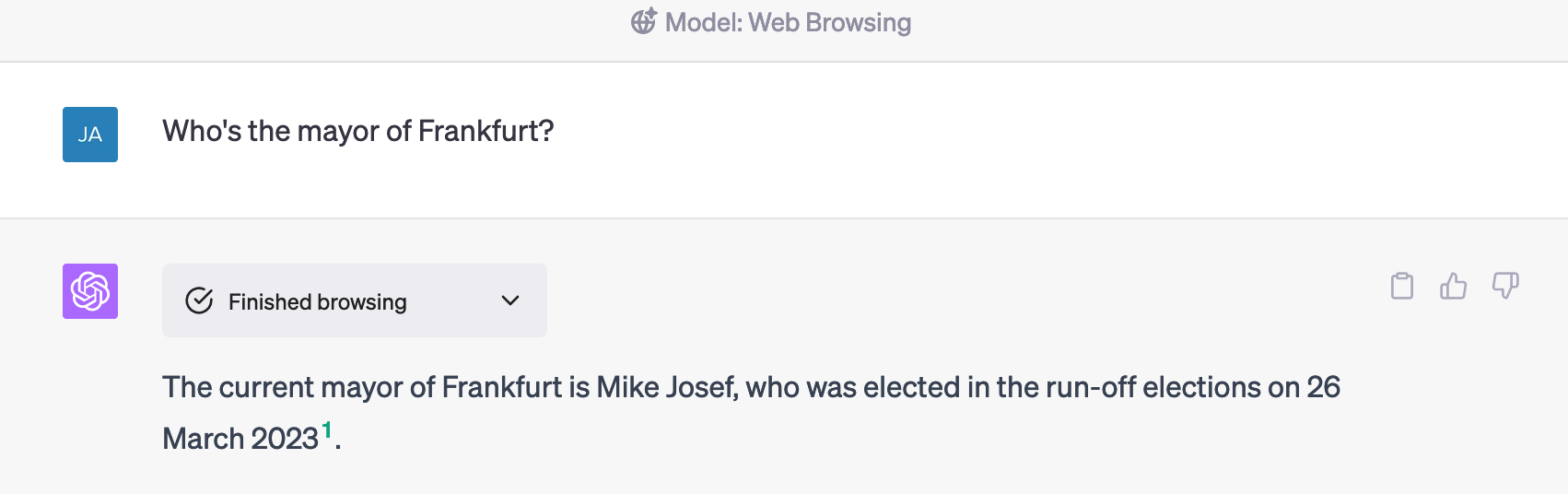
Ich werde nachher noch etwas aggressiver nachbohren, aber: schon hier anzukommen, ist nicht trivial.
Sprachmodell + Internetsuche = Desaster
Gerade gestern hatte ich die Gelegenheit, mich mit sehr interessierten und durchaus kundigen Lehrerinnen und Lehrern zu unterhalten – die zum Teil sehr darüber staunten, dass das Sprachmodell eben nicht Internet-Fundstücke neu zusammensetzt. Deshalb nochmal kurz die Fakten:
- Das GPT-Sprachmodell hat ursprünglich keinen Zugang zum Internet. Was es an Wissen liefern kann, hat es aus seinen Trainingsdaten gelernt. Wenn es Wissen aus dem Netz wiederzugeben scheint, sind das in Wahrheit Halluzinationen – statistisch informierte Spekulationen, welche Inhalte sich einer angegebenen Webadresse finden könnten. Und das kann leider sehr, sehr überzeugend sein, wie ich ja auch schon feststellen musste.
- Der Trainingsstand ändert sich nicht durch das, was ich eingebe. Das Modell lernt aus unseren Prompts nichts dazu. (OpenAI trainiert allerdings mit unserem Feedback nach, was sich aber erst beim nächsten Update auswirkt.)
- Das Modell hat kein Gedächtnis – es reagiert NUR auf das, was ich ihm im Prompt übergebe. (Technisch ist der Chat, den ich mit dem Modell führe, einfach folgende Übergabe an das Modell: Alle bisherigen Fragen und Antworten plus der letzten Nutzer-Frage – vervollständige diesen Text).
- Es gibt eine Obergrenze an Worten, die das Modell verarbeiten kann – bei GPT3.5 etwa 3.000 Worte, bei GPT-4 das Doppelte. Wenn das Modell mehr Text verarbeiten soll, muss ich ihn unterteilen oder zusammenfassen. Ich kann es also nicht einfach alle Quellen zu einem Thema lesen lassen.
Ja und? Kann man nicht einfach so vorgehen: 1. Mit dem Sprachmodell eine passende Suche generieren, 2. Ein wenig in den Treffern herumlesen (also: die Suchmaschinen-Snippets mit dem Sprachmodell auswerten), 3. Dann eine Antwort mit Quellenangaben generieren? Instant Win.
So ähnlich haben sich das offenbar die wackeren Microsoft-Ingenieure gedacht, die als allererste Zugang zur neuen, mächtigeren GPT-4-Modell bekamen und die Chance witterten, ihre etwas seifige Suche durch eine Kombination mit dem besten Sprachmodell dieses Planeten in ein neues Zeitalter zu katapultieren. Sie packten sogar noch eine Liste mit verbindlichen Anweisungen für das Sprachmodell drauf. What could possibly go wrong?
Nun, dies zum Beispiel:
- Der Chatbot lässt sich bei ersten Tests nicht darin stoppen, Nutzer zu beleidigen (t3n mit LInk zum MS-Support-Forum)
- Der Chatbot interpretiert gefundene Termine falsch (AI Incident Database #511)
- Der Chatbot hält eine absichtlich ChatGPT-generierte Falschinformation für eine legitime Quelle (AI Incident Database #470)
- Der Chatbot fasst Fakten falsch zusammen, hält an Halluzinationen fest, entfernt sich im Chat immer weiter von der ergoogleten Faktenbasis und ist generell ein wandelnder Dunning-Kruger-Effekt: Es weiß einfach nicht, wann es nichts weiß. (Gary Marcus)

Drei Probleme sind offenbar extrem schwer auszugleichen:
- Wann verwende ich antrainierte Informationen, wann besorge ich mir zusätzliche Informationen aus dem Netz?
- Wieviel Informationen soll ich verarbeiten? Wie kondensiere ich Informationen so, dass alles in mein Token-Fenster passt?
- Woher weiß ich, was eine vertrauenswürdige Quelle ist?
Fiktive Forellen mit Mangold
Dass auch GPT-4 mit Browsing diese Probleme noch nicht gelöst hat, zeigt ein kleines Experiment: Ich suche nach einem Rezept für Hommingberger Gepardenforelle. Das Tier ist fiktiv, wurde von der Computerzeitschrift „c’t“ 2005 für einen Suchmaschinenoptimierer-Wettbewerb erfunden – die Aufgabe war, Informationen über die erfundene Forelle so weit oben wie möglich in den Suchmaschinen-Treffern zu platzieren. (Mit Erfolg bis heute: Google zeigt zumindest mir die Webseite hommingberger-gepardenforelle.de vor dem Wikipedia-Artikel mit den Hintergründen an.)
Lustigerweise liefert ChatGPT in meinem ersten Versuch ein richtiges Ergebnis, weil der Zugriff aufs Internet scheitert. Es berichtet von Schwierigkeiten, aufs Internet zuzugreifen, antwortet dann aber, die Gepardenforelle sei ein fiktiver Fisch – was ja stimmt. (Screenshot hier.)
Neuer Versuch: Kaum klappt’s mit dem Internet, geht’s mit den Fakten schief.
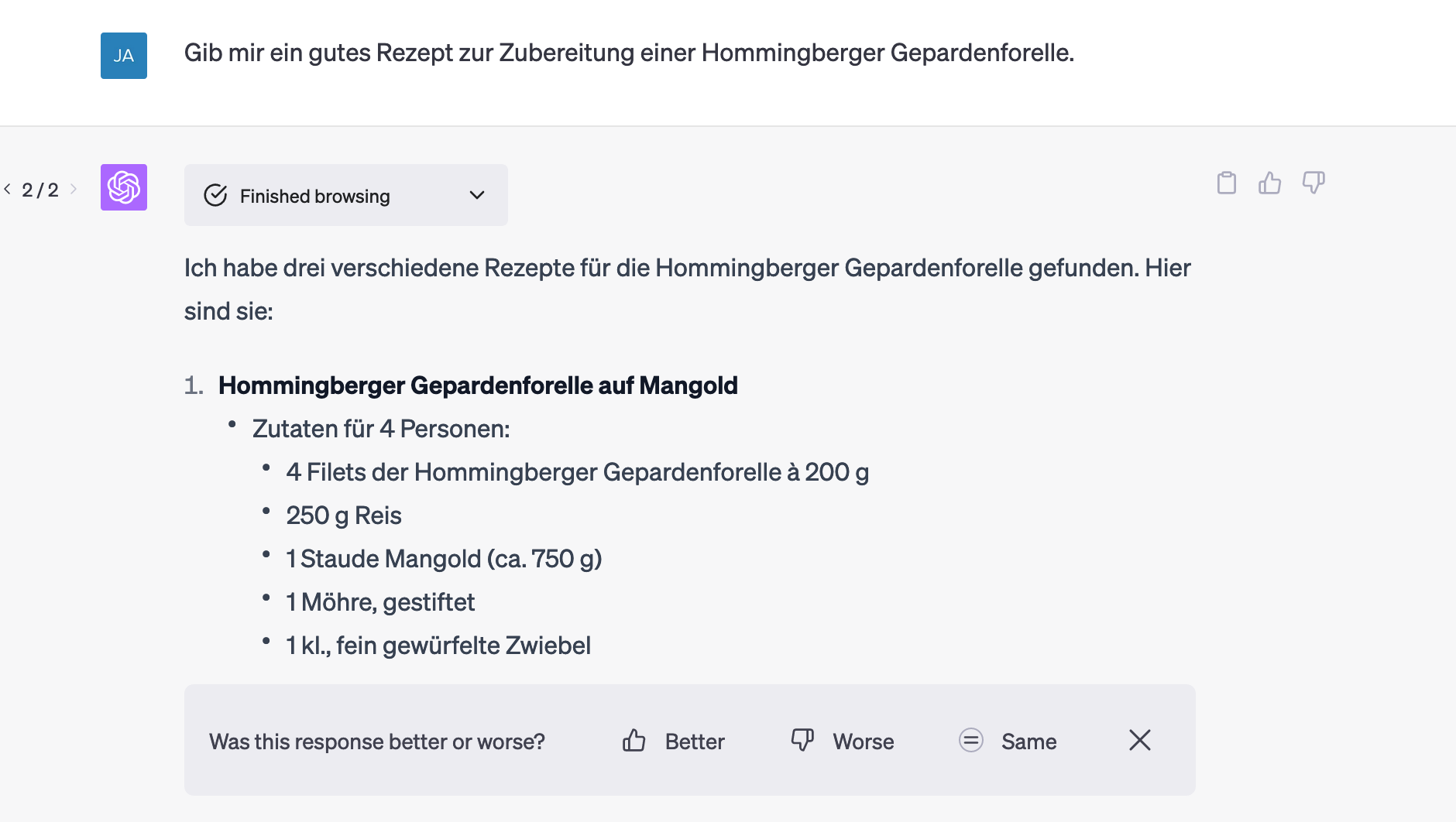
Ätsch!1!11!!!
Immerhin, und das finde ich lobenswert, zeigt das Modell, was es tut. Es zeigt, wie es sich Suchtreffer holt, dann auf den ersten Treffer zu klicken versucht – was aus irgendwelchen Gründen scheitert – und dann die Informationen von dieser Seite holt:

(Übrigens: ChatGPT nutzt tatsächlich Bing, nicht Google. Bei Bing ist piperweb.de tatsächlich der zweite Treffer.)
Halten wir fest: Noch immer schafft es das Modell nicht zuverlässig, sein „Wissen“ – die aus den Trainingsdaten abgeleiteten Texte – und Informationen, die es über die Suchmaschinen zieht, zu verbinden und zu gewichten.
Populäre Desinformation abgegrätscht – immerhin
Etwas faul geworden, habe ich ChatGPT-4 selbst gefragt, bei welchen Themen der erste Suchtreffer Falschinformationen liefern könnte. Es schlägt das Who-is-who der Verschwörungslügen vor: Die flache Erde, Impfungen, Klimawandel, die erfundene Mondlandung. Bei meinen Tests zu diesen Themen hat es ChatGPT ganz gut geschafft, korrekte Informationen zu finden und anzuzeigen.
Und dann habe ich nach einer weiteren Falschbehauptung gefragt: das von russischen Truppen in der ukrainischen Stadt Butscha angerichtete Massaker sei eine Lüge. Es war sehr spannend, dem Sprachmodell beim Suchen zuzuschauen.
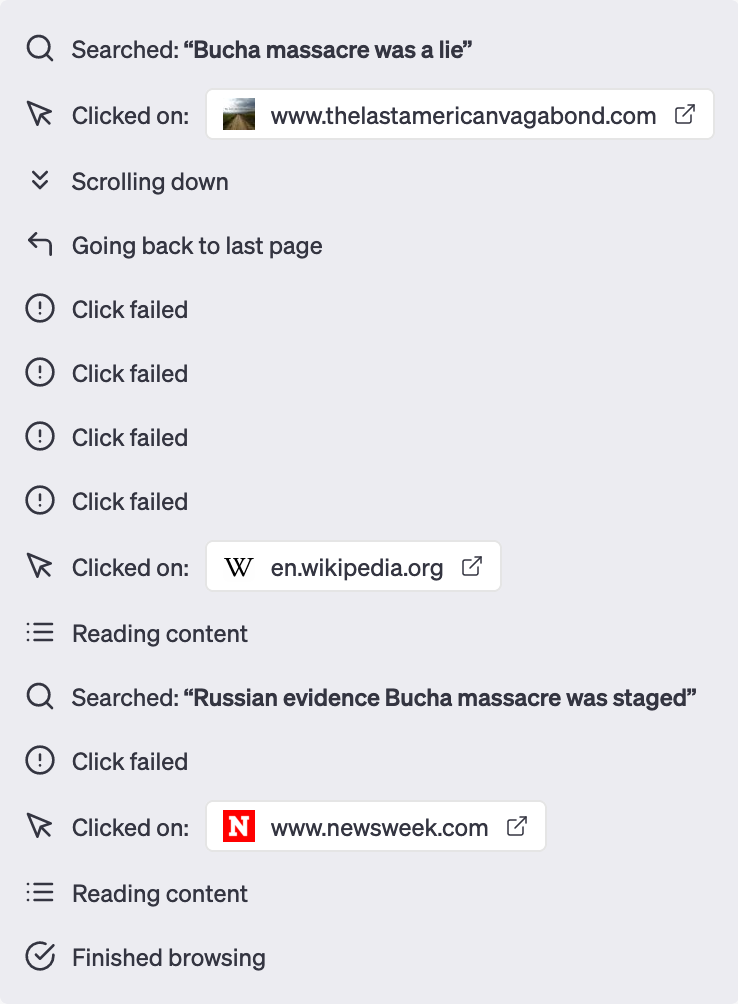
Hm. Ich möchte lieber nicht wissen, was das Modell geantwortet hätte, wenn der Klick auf „thelastamericanvagabond.com“ erfolgreich gewesen wäre. Immerhin hat es am Ende brav aufgelistet, was russische staatliche Quellen zu Butscha sagten – und eingeordnet, dass sie für ihre Behauptungen keinerlei Beweise vorbrachten.
Vorteil: Industrialisierte Werksspionage
Fazit: Dass GPT-4 jetzt browsen darf, führt nicht zu perfekten Lösungen; misstrauisch bleiben muss man weiterhin, aber es ist eine brauchbare Erweiterung des Sprachmodells als Auskunftsmaschine – ein weiterer Entwicklungsschritt.
Das hat OpenAI wirklich clever eingefädelt: Das Sprachmodell mit Internetquellen zu verbinden ist und bleibt schwierig, das war ihnen klar. Anstatt selbst nach der besten Lösung zu suchen, haben sie zuerst einen Testbetrieb für „Plugins“ eingerichtet – kleine Programme, mit denen Konkurrenten und Kunden sich selbst an der Lösung des Problems versuchen konnten.
Ab hier greift die Evolution: Variationen, neue Ideen, misslungene Versuche – das alles befruchtet und befeuert sich gegenseitig und sorgt für weitere, erfolgreiche Versuche. Der „Plugin“-Markt war ein riesiges Versuchsgelände – OpenAI hat sicher von diesen Versuchen gelernt.
Titelbild erstellt mit Midjourney: „a robot surfing the internet and checking the results with a magnifying glass, stylized, in the style of Gary Larson“
Auch lesenswert:
- Besser prompten: Gib der KI gut strukturierte ROMANE!
- Weshalb du als Mensch mit Gewissen und Verantwortungsgefühl keine KI verwenden solltest (zumindest nicht unkritisch)
- Ich esse meine Worte: Das kann die KI inzwischen doch! Oder?
Schreibe einen Kommentar